
15 Hypothesis Examples

Chris Drew (PhD)
Dr. Chris Drew is the founder of the Helpful Professor. He holds a PhD in education and has published over 20 articles in scholarly journals. He is the former editor of the Journal of Learning Development in Higher Education. [Image Descriptor: Photo of Chris]
Learn about our Editorial Process

A hypothesis is defined as a testable prediction , and is used primarily in scientific experiments as a potential or predicted outcome that scientists attempt to prove or disprove (Atkinson et al., 2021; Tan, 2022).
In my types of hypothesis article, I outlined 13 different hypotheses, including the directional hypothesis (which makes a prediction about an effect of a treatment will be positive or negative) and the associative hypothesis (which makes a prediction about the association between two variables).
This article will dive into some interesting examples of hypotheses and examine potential ways you might test each one.
Hypothesis Examples
1. “inadequate sleep decreases memory retention”.
Field: Psychology
Type: Causal Hypothesis A causal hypothesis explores the effect of one variable on another. This example posits that a lack of adequate sleep causes decreased memory retention. In other words, if you are not getting enough sleep, your ability to remember and recall information may suffer.
How to Test:
To test this hypothesis, you might devise an experiment whereby your participants are divided into two groups: one receives an average of 8 hours of sleep per night for a week, while the other gets less than the recommended sleep amount.
During this time, all participants would daily study and recall new, specific information. You’d then measure memory retention of this information for both groups using standard memory tests and compare the results.
Should the group with less sleep have statistically significant poorer memory scores, the hypothesis would be supported.
Ensuring the integrity of the experiment requires taking into account factors such as individual health differences, stress levels, and daily nutrition.
Relevant Study: Sleep loss, learning capacity and academic performance (Curcio, Ferrara & De Gennaro, 2006)
2. “Increase in Temperature Leads to Increase in Kinetic Energy”
Field: Physics
Type: Deductive Hypothesis The deductive hypothesis applies the logic of deductive reasoning – it moves from a general premise to a more specific conclusion. This specific hypothesis assumes that as temperature increases, the kinetic energy of particles also increases – that is, when you heat something up, its particles move around more rapidly.
This hypothesis could be examined by heating a gas in a controlled environment and capturing the movement of its particles as a function of temperature.
You’d gradually increase the temperature and measure the kinetic energy of the gas particles with each increment. If the kinetic energy consistently rises with the temperature, your hypothesis gets supporting evidence.
Variables such as pressure and volume of the gas would need to be held constant to ensure validity of results.
3. “Children Raised in Bilingual Homes Develop Better Cognitive Skills”
Field: Psychology/Linguistics
Type: Comparative Hypothesis The comparative hypothesis posits a difference between two or more groups based on certain variables. In this context, you might propose that children raised in bilingual homes have superior cognitive skills compared to those raised in monolingual homes.
Testing this hypothesis could involve identifying two groups of children: those raised in bilingual homes, and those raised in monolingual homes.
Cognitive skills in both groups would be evaluated using a standard cognitive ability test at different stages of development. The examination would be repeated over a significant time period for consistency.
If the group raised in bilingual homes persistently scores higher than the other, the hypothesis would thereby be supported.
The challenge for the researcher would be controlling for other variables that could impact cognitive development, such as socio-economic status, education level of parents, and parenting styles.
Relevant Study: The cognitive benefits of being bilingual (Marian & Shook, 2012)
4. “High-Fiber Diet Leads to Lower Incidences of Cardiovascular Diseases”
Field: Medicine/Nutrition
Type: Alternative Hypothesis The alternative hypothesis suggests an alternative to a null hypothesis. In this context, the implied null hypothesis could be that diet has no effect on cardiovascular health, which the alternative hypothesis contradicts by suggesting that a high-fiber diet leads to fewer instances of cardiovascular diseases.
To test this hypothesis, a longitudinal study could be conducted on two groups of participants; one adheres to a high-fiber diet, while the other follows a diet low in fiber.
After a fixed period, the cardiovascular health of participants in both groups could be analyzed and compared. If the group following a high-fiber diet has a lower number of recorded cases of cardiovascular diseases, it would provide evidence supporting the hypothesis.
Control measures should be implemented to exclude the influence of other lifestyle and genetic factors that contribute to cardiovascular health.
Relevant Study: Dietary fiber, inflammation, and cardiovascular disease (King, 2005)
5. “Gravity Influences the Directional Growth of Plants”
Field: Agronomy / Botany
Type: Explanatory Hypothesis An explanatory hypothesis attempts to explain a phenomenon. In this case, the hypothesis proposes that gravity affects how plants direct their growth – both above-ground (toward sunlight) and below-ground (towards water and other resources).
The testing could be conducted by growing plants in a rotating cylinder to create artificial gravity.
Observations on the direction of growth, over a specified period, can provide insights into the influencing factors. If plants consistently direct their growth in a manner that indicates the influence of gravitational pull, the hypothesis is substantiated.
It is crucial to ensure that other growth-influencing factors, such as light and water, are uniformly distributed so that only gravity influences the directional growth.
6. “The Implementation of Gamified Learning Improves Students’ Motivation”
Field: Education
Type: Relational Hypothesis The relational hypothesis describes the relation between two variables. Here, the hypothesis is that the implementation of gamified learning has a positive effect on the motivation of students.
To validate this proposition, two sets of classes could be compared: one that implements a learning approach with game-based elements, and another that follows a traditional learning approach.
The students’ motivation levels could be gauged by monitoring their engagement, performance, and feedback over a considerable timeframe.
If the students engaged in the gamified learning context present higher levels of motivation and achievement, the hypothesis would be supported.
Control measures ought to be put into place to account for individual differences, including prior knowledge and attitudes towards learning.
Relevant Study: Does educational gamification improve students’ motivation? (Chapman & Rich, 2018)
7. “Mathematics Anxiety Negatively Affects Performance”
Field: Educational Psychology
Type: Research Hypothesis The research hypothesis involves making a prediction that will be tested. In this case, the hypothesis proposes that a student’s anxiety about math can negatively influence their performance in math-related tasks.
To assess this hypothesis, researchers must first measure the mathematics anxiety levels of a sample of students using a validated instrument, such as the Mathematics Anxiety Rating Scale.
Then, the students’ performance in mathematics would be evaluated through standard testing. If there’s a negative correlation between the levels of math anxiety and math performance (meaning as anxiety increases, performance decreases), the hypothesis would be supported.
It would be crucial to control for relevant factors such as overall academic performance and previous mathematical achievement.
8. “Disruption of Natural Sleep Cycle Impairs Worker Productivity”
Field: Organizational Psychology
Type: Operational Hypothesis The operational hypothesis involves defining the variables in measurable terms. In this example, the hypothesis posits that disrupting the natural sleep cycle, for instance through shift work or irregular working hours, can lessen productivity among workers.
To test this hypothesis, you could collect data from workers who maintain regular working hours and those with irregular schedules.
Measuring productivity could involve examining the worker’s ability to complete tasks, the quality of their work, and their efficiency.
If workers with interrupted sleep cycles demonstrate lower productivity compared to those with regular sleep patterns, it would lend support to the hypothesis.
Consideration should be given to potential confounding variables such as job type, worker age, and overall health.
9. “Regular Physical Activity Reduces the Risk of Depression”
Field: Health Psychology
Type: Predictive Hypothesis A predictive hypothesis involves making a prediction about the outcome of a study based on the observed relationship between variables. In this case, it is hypothesized that individuals who engage in regular physical activity are less likely to suffer from depression.
Longitudinal studies would suit to test this hypothesis, tracking participants’ levels of physical activity and their mental health status over time.
The level of physical activity could be self-reported or monitored, while mental health status could be assessed using standard diagnostic tools or surveys.
If data analysis shows that participants maintaining regular physical activity have a lower incidence of depression, this would endorse the hypothesis.
However, care should be taken to control other lifestyle and behavioral factors that could intervene with the results.
Relevant Study: Regular physical exercise and its association with depression (Kim, 2022)
10. “Regular Meditation Enhances Emotional Stability”
Type: Empirical Hypothesis In the empirical hypothesis, predictions are based on amassed empirical evidence . This particular hypothesis theorizes that frequent meditation leads to improved emotional stability, resonating with numerous studies linking meditation to a variety of psychological benefits.
Earlier studies reported some correlations, but to test this hypothesis directly, you’d organize an experiment where one group meditates regularly over a set period while a control group doesn’t.
Both groups’ emotional stability levels would be measured at the start and end of the experiment using a validated emotional stability assessment.
If regular meditators display noticeable improvements in emotional stability compared to the control group, the hypothesis gains credit.
You’d have to ensure a similar emotional baseline for all participants at the start to avoid skewed results.
11. “Children Exposed to Reading at an Early Age Show Superior Academic Progress”
Type: Directional Hypothesis The directional hypothesis predicts the direction of an expected relationship between variables. Here, the hypothesis anticipates that early exposure to reading positively affects a child’s academic advancement.
A longitudinal study tracking children’s reading habits from an early age and their consequent academic performance could validate this hypothesis.
Parents could report their children’s exposure to reading at home, while standardized school exam results would provide a measure of academic achievement.
If the children exposed to early reading consistently perform better acadically, it gives weight to the hypothesis.
However, it would be important to control for variables that might impact academic performance, such as socioeconomic background, parental education level, and school quality.
12. “Adopting Energy-efficient Technologies Reduces Carbon Footprint of Industries”
Field: Environmental Science
Type: Descriptive Hypothesis A descriptive hypothesis predicts the existence of an association or pattern related to variables. In this scenario, the hypothesis suggests that industries adopting energy-efficient technologies will resultantly show a reduced carbon footprint.
Global industries making use of energy-efficient technologies could track their carbon emissions over time. At the same time, others not implementing such technologies continue their regular tracking.
After a defined time, the carbon emission data of both groups could be compared. If industries that adopted energy-efficient technologies demonstrate a notable reduction in their carbon footprints, the hypothesis would hold strong.
In the experiment, you would exclude variations brought by factors such as industry type, size, and location.
13. “Reduced Screen Time Improves Sleep Quality”
Type: Simple Hypothesis The simple hypothesis is a prediction about the relationship between two variables, excluding any other variables from consideration. This example posits that by reducing time spent on devices like smartphones and computers, an individual should experience improved sleep quality.
A sample group would need to reduce their daily screen time for a pre-determined period. Sleep quality before and after the reduction could be measured using self-report sleep diaries and objective measures like actigraphy, monitoring movement and wakefulness during sleep.
If the data shows that sleep quality improved post the screen time reduction, the hypothesis would be validated.
Other aspects affecting sleep quality, like caffeine intake, should be controlled during the experiment.
Relevant Study: Screen time use impacts low‐income preschool children’s sleep quality, tiredness, and ability to fall asleep (Waller et al., 2021)
14. Engaging in Brain-Training Games Improves Cognitive Functioning in Elderly
Field: Gerontology
Type: Inductive Hypothesis Inductive hypotheses are based on observations leading to broader generalizations and theories. In this context, the hypothesis deduces from observed instances that engaging in brain-training games can help improve cognitive functioning in the elderly.
A longitudinal study could be conducted where an experimental group of elderly people partakes in regular brain-training games.
Their cognitive functioning could be assessed at the start of the study and at regular intervals using standard neuropsychological tests.
If the group engaging in brain-training games shows better cognitive functioning scores over time compared to a control group not playing these games, the hypothesis would be supported.
15. Farming Practices Influence Soil Erosion Rates
Type: Null Hypothesis A null hypothesis is a negative statement assuming no relationship or difference between variables. The hypothesis in this context asserts there’s no effect of different farming practices on the rates of soil erosion.
Comparing soil erosion rates in areas with different farming practices over a considerable timeframe could help test this hypothesis.
If, statistically, the farming practices do not lead to differences in soil erosion rates, the null hypothesis is accepted.
However, if marked variation appears, the null hypothesis is rejected, meaning farming practices do influence soil erosion rates. It would be crucial to control for external factors like weather, soil type, and natural vegetation.
The variety of hypotheses mentioned above underscores the diversity of research constructs inherent in different fields, each with its unique purpose and way of testing.
While researchers may develop hypotheses primarily as tools to define and narrow the focus of the study, these hypotheses also serve as valuable guiding forces for the data collection and analysis procedures, making the research process more efficient and direction-focused.
Hypotheses serve as a compass for any form of academic research. The diverse examples provided, from Psychology to Educational Studies, Environmental Science to Gerontology, clearly demonstrate how certain hypotheses suit specific fields more aptly than others.
It is important to underline that although these varied hypotheses differ in their structure and methods of testing, each endorses the fundamental value of empiricism in research. Evidence-based decision making remains at the heart of scholarly inquiry, regardless of the research field, thus aligning all hypotheses to the core purpose of scientific investigation.
Testing hypotheses is an essential part of the scientific method . By doing so, researchers can either confirm their predictions, giving further validity to an existing theory, or they might uncover new insights that could potentially shift the field’s understanding of a particular phenomenon. In either case, hypotheses serve as the stepping stones for scientific exploration and discovery.
Atkinson, P., Delamont, S., Cernat, A., Sakshaug, J. W., & Williams, R. A. (2021). SAGE research methods foundations . SAGE Publications Ltd.
Curcio, G., Ferrara, M., & De Gennaro, L. (2006). Sleep loss, learning capacity and academic performance. Sleep medicine reviews , 10 (5), 323-337.
Kim, J. H. (2022). Regular physical exercise and its association with depression: A population-based study short title: Exercise and depression. Psychiatry Research , 309 , 114406.
King, D. E. (2005). Dietary fiber, inflammation, and cardiovascular disease. Molecular nutrition & food research , 49 (6), 594-600.
Marian, V., & Shook, A. (2012, September). The cognitive benefits of being bilingual. In Cerebrum: the Dana forum on brain science (Vol. 2012). Dana Foundation.
Tan, W. C. K. (2022). Research Methods: A Practical Guide For Students And Researchers (Second Edition) . World Scientific Publishing Company.
Waller, N. A., Zhang, N., Cocci, A. H., D’Agostino, C., Wesolek‐Greenson, S., Wheelock, K., … & Resnicow, K. (2021). Screen time use impacts low‐income preschool children’s sleep quality, tiredness, and ability to fall asleep. Child: care, health and development, 47 (5), 618-626.

- Chris Drew (PhD) https://helpfulprofessor.com/author/chris-drew-phd-2/ 10 Reasons you’re Perpetually Single
- Chris Drew (PhD) https://helpfulprofessor.com/author/chris-drew-phd-2/ 20 Montessori Toddler Bedrooms (Design Inspiration)
- Chris Drew (PhD) https://helpfulprofessor.com/author/chris-drew-phd-2/ 21 Montessori Homeschool Setups
- Chris Drew (PhD) https://helpfulprofessor.com/author/chris-drew-phd-2/ 101 Hidden Talents Examples
Leave a Comment Cancel Reply
Your email address will not be published. Required fields are marked *
Educational resources and simple solutions for your research journey

What is a Research Hypothesis: How to Write it, Types, and Examples
Any research begins with a research question and a research hypothesis . A research question alone may not suffice to design the experiment(s) needed to answer it. A hypothesis is central to the scientific method. But what is a hypothesis ? A hypothesis is a testable statement that proposes a possible explanation to a phenomenon, and it may include a prediction. Next, you may ask what is a research hypothesis ? Simply put, a research hypothesis is a prediction or educated guess about the relationship between the variables that you want to investigate.
It is important to be thorough when developing your research hypothesis. Shortcomings in the framing of a hypothesis can affect the study design and the results. A better understanding of the research hypothesis definition and characteristics of a good hypothesis will make it easier for you to develop your own hypothesis for your research. Let’s dive in to know more about the types of research hypothesis , how to write a research hypothesis , and some research hypothesis examples .
Table of Contents
What is a hypothesis ?
A hypothesis is based on the existing body of knowledge in a study area. Framed before the data are collected, a hypothesis states the tentative relationship between independent and dependent variables, along with a prediction of the outcome.
What is a research hypothesis ?
Young researchers starting out their journey are usually brimming with questions like “ What is a hypothesis ?” “ What is a research hypothesis ?” “How can I write a good research hypothesis ?”
A research hypothesis is a statement that proposes a possible explanation for an observable phenomenon or pattern. It guides the direction of a study and predicts the outcome of the investigation. A research hypothesis is testable, i.e., it can be supported or disproven through experimentation or observation.

Characteristics of a good hypothesis
Here are the characteristics of a good hypothesis :
- Clearly formulated and free of language errors and ambiguity
- Concise and not unnecessarily verbose
- Has clearly defined variables
- Testable and stated in a way that allows for it to be disproven
- Can be tested using a research design that is feasible, ethical, and practical
- Specific and relevant to the research problem
- Rooted in a thorough literature search
- Can generate new knowledge or understanding.
How to create an effective research hypothesis
A study begins with the formulation of a research question. A researcher then performs background research. This background information forms the basis for building a good research hypothesis . The researcher then performs experiments, collects, and analyzes the data, interprets the findings, and ultimately, determines if the findings support or negate the original hypothesis.
Let’s look at each step for creating an effective, testable, and good research hypothesis :
- Identify a research problem or question: Start by identifying a specific research problem.
- Review the literature: Conduct an in-depth review of the existing literature related to the research problem to grasp the current knowledge and gaps in the field.
- Formulate a clear and testable hypothesis : Based on the research question, use existing knowledge to form a clear and testable hypothesis . The hypothesis should state a predicted relationship between two or more variables that can be measured and manipulated. Improve the original draft till it is clear and meaningful.
- State the null hypothesis: The null hypothesis is a statement that there is no relationship between the variables you are studying.
- Define the population and sample: Clearly define the population you are studying and the sample you will be using for your research.
- Select appropriate methods for testing the hypothesis: Select appropriate research methods, such as experiments, surveys, or observational studies, which will allow you to test your research hypothesis .
Remember that creating a research hypothesis is an iterative process, i.e., you might have to revise it based on the data you collect. You may need to test and reject several hypotheses before answering the research problem.
How to write a research hypothesis
When you start writing a research hypothesis , you use an “if–then” statement format, which states the predicted relationship between two or more variables. Clearly identify the independent variables (the variables being changed) and the dependent variables (the variables being measured), as well as the population you are studying. Review and revise your hypothesis as needed.
An example of a research hypothesis in this format is as follows:
“ If [athletes] follow [cold water showers daily], then their [endurance] increases.”
Population: athletes
Independent variable: daily cold water showers
Dependent variable: endurance
You may have understood the characteristics of a good hypothesis . But note that a research hypothesis is not always confirmed; a researcher should be prepared to accept or reject the hypothesis based on the study findings.

Research hypothesis checklist
Following from above, here is a 10-point checklist for a good research hypothesis :
- Testable: A research hypothesis should be able to be tested via experimentation or observation.
- Specific: A research hypothesis should clearly state the relationship between the variables being studied.
- Based on prior research: A research hypothesis should be based on existing knowledge and previous research in the field.
- Falsifiable: A research hypothesis should be able to be disproven through testing.
- Clear and concise: A research hypothesis should be stated in a clear and concise manner.
- Logical: A research hypothesis should be logical and consistent with current understanding of the subject.
- Relevant: A research hypothesis should be relevant to the research question and objectives.
- Feasible: A research hypothesis should be feasible to test within the scope of the study.
- Reflects the population: A research hypothesis should consider the population or sample being studied.
- Uncomplicated: A good research hypothesis is written in a way that is easy for the target audience to understand.
By following this research hypothesis checklist , you will be able to create a research hypothesis that is strong, well-constructed, and more likely to yield meaningful results.

Types of research hypothesis
Different types of research hypothesis are used in scientific research:
1. Null hypothesis:
A null hypothesis states that there is no change in the dependent variable due to changes to the independent variable. This means that the results are due to chance and are not significant. A null hypothesis is denoted as H0 and is stated as the opposite of what the alternative hypothesis states.
Example: “ The newly identified virus is not zoonotic .”
2. Alternative hypothesis:
This states that there is a significant difference or relationship between the variables being studied. It is denoted as H1 or Ha and is usually accepted or rejected in favor of the null hypothesis.
Example: “ The newly identified virus is zoonotic .”
3. Directional hypothesis :
This specifies the direction of the relationship or difference between variables; therefore, it tends to use terms like increase, decrease, positive, negative, more, or less.
Example: “ The inclusion of intervention X decreases infant mortality compared to the original treatment .”
4. Non-directional hypothesis:
While it does not predict the exact direction or nature of the relationship between the two variables, a non-directional hypothesis states the existence of a relationship or difference between variables but not the direction, nature, or magnitude of the relationship. A non-directional hypothesis may be used when there is no underlying theory or when findings contradict previous research.
Example, “ Cats and dogs differ in the amount of affection they express .”
5. Simple hypothesis :
A simple hypothesis only predicts the relationship between one independent and another independent variable.
Example: “ Applying sunscreen every day slows skin aging .”
6 . Complex hypothesis :
A complex hypothesis states the relationship or difference between two or more independent and dependent variables.
Example: “ Applying sunscreen every day slows skin aging, reduces sun burn, and reduces the chances of skin cancer .” (Here, the three dependent variables are slowing skin aging, reducing sun burn, and reducing the chances of skin cancer.)
7. Associative hypothesis:
An associative hypothesis states that a change in one variable results in the change of the other variable. The associative hypothesis defines interdependency between variables.
Example: “ There is a positive association between physical activity levels and overall health .”
8 . Causal hypothesis:
A causal hypothesis proposes a cause-and-effect interaction between variables.
Example: “ Long-term alcohol use causes liver damage .”
Note that some of the types of research hypothesis mentioned above might overlap. The types of hypothesis chosen will depend on the research question and the objective of the study.

Research hypothesis examples
Here are some good research hypothesis examples :
“The use of a specific type of therapy will lead to a reduction in symptoms of depression in individuals with a history of major depressive disorder.”
“Providing educational interventions on healthy eating habits will result in weight loss in overweight individuals.”
“Plants that are exposed to certain types of music will grow taller than those that are not exposed to music.”
“The use of the plant growth regulator X will lead to an increase in the number of flowers produced by plants.”
Characteristics that make a research hypothesis weak are unclear variables, unoriginality, being too general or too vague, and being untestable. A weak hypothesis leads to weak research and improper methods.
Some bad research hypothesis examples (and the reasons why they are “bad”) are as follows:
“This study will show that treatment X is better than any other treatment . ” (This statement is not testable, too broad, and does not consider other treatments that may be effective.)
“This study will prove that this type of therapy is effective for all mental disorders . ” (This statement is too broad and not testable as mental disorders are complex and different disorders may respond differently to different types of therapy.)
“Plants can communicate with each other through telepathy . ” (This statement is not testable and lacks a scientific basis.)
Importance of testable hypothesis
If a research hypothesis is not testable, the results will not prove or disprove anything meaningful. The conclusions will be vague at best. A testable hypothesis helps a researcher focus on the study outcome and understand the implication of the question and the different variables involved. A testable hypothesis helps a researcher make precise predictions based on prior research.
To be considered testable, there must be a way to prove that the hypothesis is true or false; further, the results of the hypothesis must be reproducible.

Frequently Asked Questions (FAQs) on research hypothesis
1. What is the difference between research question and research hypothesis ?
A research question defines the problem and helps outline the study objective(s). It is an open-ended statement that is exploratory or probing in nature. Therefore, it does not make predictions or assumptions. It helps a researcher identify what information to collect. A research hypothesis , however, is a specific, testable prediction about the relationship between variables. Accordingly, it guides the study design and data analysis approach.
2. When to reject null hypothesis ?
A null hypothesis should be rejected when the evidence from a statistical test shows that it is unlikely to be true. This happens when the test statistic (e.g., p -value) is less than the defined significance level (e.g., 0.05). Rejecting the null hypothesis does not necessarily mean that the alternative hypothesis is true; it simply means that the evidence found is not compatible with the null hypothesis.
3. How can I be sure my hypothesis is testable?
A testable hypothesis should be specific and measurable, and it should state a clear relationship between variables that can be tested with data. To ensure that your hypothesis is testable, consider the following:
- Clearly define the key variables in your hypothesis. You should be able to measure and manipulate these variables in a way that allows you to test the hypothesis.
- The hypothesis should predict a specific outcome or relationship between variables that can be measured or quantified.
- You should be able to collect the necessary data within the constraints of your study.
- It should be possible for other researchers to replicate your study, using the same methods and variables.
- Your hypothesis should be testable by using appropriate statistical analysis techniques, so you can draw conclusions, and make inferences about the population from the sample data.
- The hypothesis should be able to be disproven or rejected through the collection of data.
4. How do I revise my research hypothesis if my data does not support it?
If your data does not support your research hypothesis , you will need to revise it or develop a new one. You should examine your data carefully and identify any patterns or anomalies, re-examine your research question, and/or revisit your theory to look for any alternative explanations for your results. Based on your review of the data, literature, and theories, modify your research hypothesis to better align it with the results you obtained. Use your revised hypothesis to guide your research design and data collection. It is important to remain objective throughout the process.
5. I am performing exploratory research. Do I need to formulate a research hypothesis?
As opposed to “confirmatory” research, where a researcher has some idea about the relationship between the variables under investigation, exploratory research (or hypothesis-generating research) looks into a completely new topic about which limited information is available. Therefore, the researcher will not have any prior hypotheses. In such cases, a researcher will need to develop a post-hoc hypothesis. A post-hoc research hypothesis is generated after these results are known.
6. How is a research hypothesis different from a research question?
A research question is an inquiry about a specific topic or phenomenon, typically expressed as a question. It seeks to explore and understand a particular aspect of the research subject. In contrast, a research hypothesis is a specific statement or prediction that suggests an expected relationship between variables. It is formulated based on existing knowledge or theories and guides the research design and data analysis.
7. Can a research hypothesis change during the research process?
Yes, research hypotheses can change during the research process. As researchers collect and analyze data, new insights and information may emerge that require modification or refinement of the initial hypotheses. This can be due to unexpected findings, limitations in the original hypotheses, or the need to explore additional dimensions of the research topic. Flexibility is crucial in research, allowing for adaptation and adjustment of hypotheses to align with the evolving understanding of the subject matter.
8. How many hypotheses should be included in a research study?
The number of research hypotheses in a research study varies depending on the nature and scope of the research. It is not necessary to have multiple hypotheses in every study. Some studies may have only one primary hypothesis, while others may have several related hypotheses. The number of hypotheses should be determined based on the research objectives, research questions, and the complexity of the research topic. It is important to ensure that the hypotheses are focused, testable, and directly related to the research aims.
9. Can research hypotheses be used in qualitative research?
Yes, research hypotheses can be used in qualitative research, although they are more commonly associated with quantitative research. In qualitative research, hypotheses may be formulated as tentative or exploratory statements that guide the investigation. Instead of testing hypotheses through statistical analysis, qualitative researchers may use the hypotheses to guide data collection and analysis, seeking to uncover patterns, themes, or relationships within the qualitative data. The emphasis in qualitative research is often on generating insights and understanding rather than confirming or rejecting specific research hypotheses through statistical testing.
Editage All Access is a subscription-based platform that unifies the best AI tools and services designed to speed up, simplify, and streamline every step of a researcher’s journey. The Editage All Access Pack is a one-of-a-kind subscription that unlocks full access to an AI writing assistant, literature recommender, journal finder, scientific illustration tool, and exclusive discounts on professional publication services from Editage.
Based on 22+ years of experience in academia, Editage All Access empowers researchers to put their best research forward and move closer to success. Explore our top AI Tools pack, AI Tools + Publication Services pack, or Build Your Own Plan. Find everything a researcher needs to succeed, all in one place – Get All Access now starting at just $14 a month !
Related Posts

Back to School – Lock-in All Access Pack for a Year at the Best Price

Journal Turnaround Time: Researcher.Life and Scholarly Intelligence Join Hands to Empower Researchers with Publication Time Insights
- Ethical Theory
Comparative Hypotheses for Technology Analysis
- In book: Global Encyclopedia of Public Administration, Public Policy, and Governance (pp.1-8)
- Publisher: Springer Nature Switzerland

- Italian National Research Council
Discover the world's research
- 25+ million members
- 160+ million publication pages
- 2.3+ billion citations
- SENSORS-BASEL

- J ENG TECHNOL MANAGE
- TECHNOL FORECAST SOC

- Recruit researchers
- Join for free
- Login Email Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google Welcome back! Please log in. Email · Hint Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google No account? Sign up
Ohio State nav bar
The Ohio State University
- BuckeyeLink
- Find People
- Search Ohio State
Research Questions & Hypotheses
Generally, in quantitative studies, reviewers expect hypotheses rather than research questions. However, both research questions and hypotheses serve different purposes and can be beneficial when used together.
Research Questions
Clarify the research’s aim (farrugia et al., 2010).
- Research often begins with an interest in a topic, but a deep understanding of the subject is crucial to formulate an appropriate research question.
- Descriptive: “What factors most influence the academic achievement of senior high school students?”
- Comparative: “What is the performance difference between teaching methods A and B?”
- Relationship-based: “What is the relationship between self-efficacy and academic achievement?”
- Increasing knowledge about a subject can be achieved through systematic literature reviews, in-depth interviews with patients (and proxies), focus groups, and consultations with field experts.
- Some funding bodies, like the Canadian Institute for Health Research, recommend conducting a systematic review or a pilot study before seeking grants for full trials.
- The presence of multiple research questions in a study can complicate the design, statistical analysis, and feasibility.
- It’s advisable to focus on a single primary research question for the study.
- The primary question, clearly stated at the end of a grant proposal’s introduction, usually specifies the study population, intervention, and other relevant factors.
- The FINER criteria underscore aspects that can enhance the chances of a successful research project, including specifying the population of interest, aligning with scientific and public interest, clinical relevance, and contribution to the field, while complying with ethical and national research standards.
| Feasible | ||
| Interesting | ||
| Novel | ||
| Ethical | ||
| Relevant |
- The P ICOT approach is crucial in developing the study’s framework and protocol, influencing inclusion and exclusion criteria and identifying patient groups for inclusion.
| Population (patients) | ||
| Intervention (for intervention studies only) | ||
| Comparison group | ||
| Outcome of interest | ||
| Time |
- Defining the specific population, intervention, comparator, and outcome helps in selecting the right outcome measurement tool.
- The more precise the population definition and stricter the inclusion and exclusion criteria, the more significant the impact on the interpretation, applicability, and generalizability of the research findings.
- A restricted study population enhances internal validity but may limit the study’s external validity and generalizability to clinical practice.
- A broadly defined study population may better reflect clinical practice but could increase bias and reduce internal validity.
- An inadequately formulated research question can negatively impact study design, potentially leading to ineffective outcomes and affecting publication prospects.
Checklist: Good research questions for social science projects (Panke, 2018)
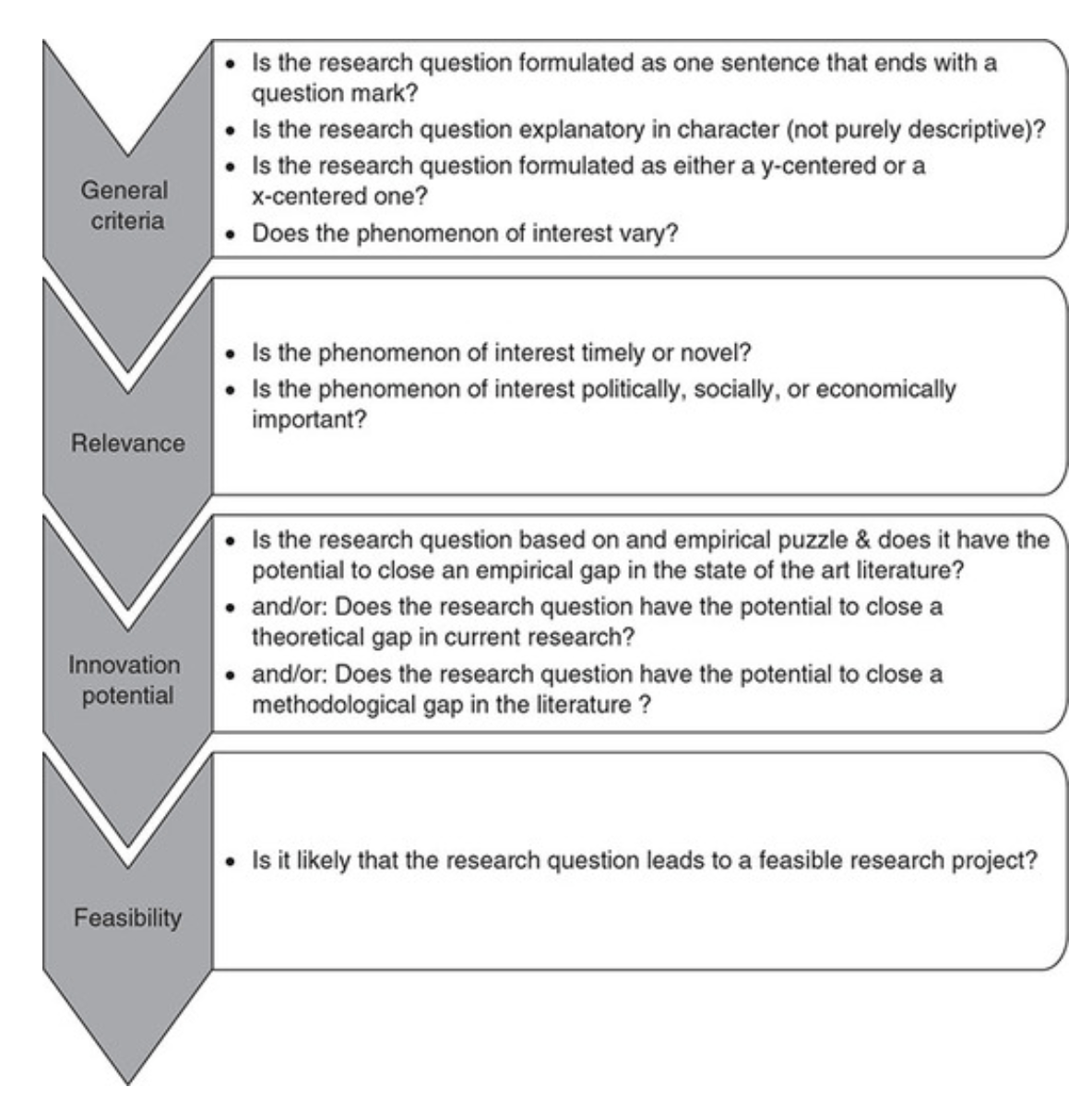
Research Hypotheses
Present the researcher’s predictions based on specific statements.
- These statements define the research problem or issue and indicate the direction of the researcher’s predictions.
- Formulating the research question and hypothesis from existing data (e.g., a database) can lead to multiple statistical comparisons and potentially spurious findings due to chance.
- The research or clinical hypothesis, derived from the research question, shapes the study’s key elements: sampling strategy, intervention, comparison, and outcome variables.
- Hypotheses can express a single outcome or multiple outcomes.
- After statistical testing, the null hypothesis is either rejected or not rejected based on whether the study’s findings are statistically significant.
- Hypothesis testing helps determine if observed findings are due to true differences and not chance.
- Hypotheses can be 1-sided (specific direction of difference) or 2-sided (presence of a difference without specifying direction).
- 2-sided hypotheses are generally preferred unless there’s a strong justification for a 1-sided hypothesis.
- A solid research hypothesis, informed by a good research question, influences the research design and paves the way for defining clear research objectives.
Types of Research Hypothesis
- In a Y-centered research design, the focus is on the dependent variable (DV) which is specified in the research question. Theories are then used to identify independent variables (IV) and explain their causal relationship with the DV.
- Example: “An increase in teacher-led instructional time (IV) is likely to improve student reading comprehension scores (DV), because extensive guided practice under expert supervision enhances learning retention and skill mastery.”
- Hypothesis Explanation: The dependent variable (student reading comprehension scores) is the focus, and the hypothesis explores how changes in the independent variable (teacher-led instructional time) affect it.
- In X-centered research designs, the independent variable is specified in the research question. Theories are used to determine potential dependent variables and the causal mechanisms at play.
- Example: “Implementing technology-based learning tools (IV) is likely to enhance student engagement in the classroom (DV), because interactive and multimedia content increases student interest and participation.”
- Hypothesis Explanation: The independent variable (technology-based learning tools) is the focus, with the hypothesis exploring its impact on a potential dependent variable (student engagement).
- Probabilistic hypotheses suggest that changes in the independent variable are likely to lead to changes in the dependent variable in a predictable manner, but not with absolute certainty.
- Example: “The more teachers engage in professional development programs (IV), the more their teaching effectiveness (DV) is likely to improve, because continuous training updates pedagogical skills and knowledge.”
- Hypothesis Explanation: This hypothesis implies a probable relationship between the extent of professional development (IV) and teaching effectiveness (DV).
- Deterministic hypotheses state that a specific change in the independent variable will lead to a specific change in the dependent variable, implying a more direct and certain relationship.
- Example: “If the school curriculum changes from traditional lecture-based methods to project-based learning (IV), then student collaboration skills (DV) are expected to improve because project-based learning inherently requires teamwork and peer interaction.”
- Hypothesis Explanation: This hypothesis presumes a direct and definite outcome (improvement in collaboration skills) resulting from a specific change in the teaching method.
- Example : “Students who identify as visual learners will score higher on tests that are presented in a visually rich format compared to tests presented in a text-only format.”
- Explanation : This hypothesis aims to describe the potential difference in test scores between visual learners taking visually rich tests and text-only tests, without implying a direct cause-and-effect relationship.
- Example : “Teaching method A will improve student performance more than method B.”
- Explanation : This hypothesis compares the effectiveness of two different teaching methods, suggesting that one will lead to better student performance than the other. It implies a direct comparison but does not necessarily establish a causal mechanism.
- Example : “Students with higher self-efficacy will show higher levels of academic achievement.”
- Explanation : This hypothesis predicts a relationship between the variable of self-efficacy and academic achievement. Unlike a causal hypothesis, it does not necessarily suggest that one variable causes changes in the other, but rather that they are related in some way.
Tips for developing research questions and hypotheses for research studies
- Perform a systematic literature review (if one has not been done) to increase knowledge and familiarity with the topic and to assist with research development.
- Learn about current trends and technological advances on the topic.
- Seek careful input from experts, mentors, colleagues, and collaborators to refine your research question as this will aid in developing the research question and guide the research study.
- Use the FINER criteria in the development of the research question.
- Ensure that the research question follows PICOT format.
- Develop a research hypothesis from the research question.
- Ensure that the research question and objectives are answerable, feasible, and clinically relevant.
If your research hypotheses are derived from your research questions, particularly when multiple hypotheses address a single question, it’s recommended to use both research questions and hypotheses. However, if this isn’t the case, using hypotheses over research questions is advised. It’s important to note these are general guidelines, not strict rules. If you opt not to use hypotheses, consult with your supervisor for the best approach.
Farrugia, P., Petrisor, B. A., Farrokhyar, F., & Bhandari, M. (2010). Practical tips for surgical research: Research questions, hypotheses and objectives. Canadian journal of surgery. Journal canadien de chirurgie , 53 (4), 278–281.
Hulley, S. B., Cummings, S. R., Browner, W. S., Grady, D., & Newman, T. B. (2007). Designing clinical research. Philadelphia.
Panke, D. (2018). Research design & method selection: Making good choices in the social sciences. Research Design & Method Selection , 1-368.
- Research Process
- Manuscript Preparation
- Manuscript Review
- Publication Process
- Publication Recognition
- Language Editing Services
- Translation Services

Step-by-Step Guide: How to Craft a Strong Research Hypothesis
- 4 minute read
- 363.3K views
Table of Contents
A research hypothesis is a concise statement about the expected result of an experiment or project. In many ways, a research hypothesis represents the starting point for a scientific endeavor, as it establishes a tentative assumption that is eventually substantiated or falsified, ultimately improving our certainty about the subject investigated.
To help you with this and ease the process, in this article, we discuss the purpose of research hypotheses and list the most essential qualities of a compelling hypothesis. Let’s find out!
How to Craft a Research Hypothesis
Crafting a research hypothesis begins with a comprehensive literature review to identify a knowledge gap in your field. Once you find a question or problem, come up with a possible answer or explanation, which becomes your hypothesis. Now think about the specific methods of experimentation that can prove or disprove the hypothesis, which ultimately lead to the results of the study.
Enlisted below are some standard formats in which you can formulate a hypothesis¹ :
- A hypothesis can use the if/then format when it seeks to explore the correlation between two variables in a study primarily.
Example: If administered drug X, then patients will experience reduced fatigue from cancer treatment.
- A hypothesis can adopt when X/then Y format when it primarily aims to expose a connection between two variables
Example: When workers spend a significant portion of their waking hours in sedentary work , then they experience a greater frequency of digestive problems.
- A hypothesis can also take the form of a direct statement.
Example: Drug X and drug Y reduce the risk of cognitive decline through the same chemical pathways
What are the Features of an Effective Hypothesis?
Hypotheses in research need to satisfy specific criteria to be considered scientifically rigorous. Here are the most notable qualities of a strong hypothesis:
- Testability: Ensure the hypothesis allows you to work towards observable and testable results.
- Brevity and objectivity: Present your hypothesis as a brief statement and avoid wordiness.
- Clarity and Relevance: The hypothesis should reflect a clear idea of what we know and what we expect to find out about a phenomenon and address the significant knowledge gap relevant to a field of study.
Understanding Null and Alternative Hypotheses in Research
There are two types of hypotheses used commonly in research that aid statistical analyses. These are known as the null hypothesis and the alternative hypothesis . A null hypothesis is a statement assumed to be factual in the initial phase of the study.
For example, if a researcher is testing the efficacy of a new drug, then the null hypothesis will posit that the drug has no benefits compared to an inactive control or placebo . Suppose the data collected through a drug trial leads a researcher to reject the null hypothesis. In that case, it is considered to substantiate the alternative hypothesis in the above example, that the new drug provides benefits compared to the placebo.
Let’s take a closer look at the null hypothesis and alternative hypothesis with two more examples:
Null Hypothesis:
The rate of decline in the number of species in habitat X in the last year is the same as in the last 100 years when controlled for all factors except the recent wildfires.
In the next experiment, the researcher will experimentally reject this null hypothesis in order to confirm the following alternative hypothesis :
The rate of decline in the number of species in habitat X in the last year is different from the rate of decline in the last 100 years when controlled for all factors other than the recent wildfires.
In the pair of null and alternative hypotheses stated above, a statistical comparison of the rate of species decline over a century and the preceding year will help the research experimentally test the null hypothesis, helping to draw scientifically valid conclusions about two factors—wildfires and species decline.
We also recommend that researchers pay attention to contextual echoes and connections when writing research hypotheses. Research hypotheses are often closely linked to the introduction ² , such as the context of the study, and can similarly influence the reader’s judgment of the relevance and validity of the research hypothesis.
Seasoned experts, such as professionals at Elsevier Language Services, guide authors on how to best embed a hypothesis within an article so that it communicates relevance and credibility. Contact us if you want help in ensuring readers find your hypothesis robust and unbiased.
References
- Hypotheses – The University Writing Center. (n.d.). https://writingcenter.tamu.edu/writing-speaking-guides/hypotheses
- Shaping the research question and hypothesis. (n.d.). Students. https://students.unimelb.edu.au/academic-skills/graduate-research-services/writing-thesis-sections-part-2/shaping-the-research-question-and-hypothesis

Systematic Literature Review or Literature Review?

How to Write an Effective Problem Statement for Your Research Paper
You may also like.

Submission 101: What format should be used for academic papers?

Page-Turner Articles are More Than Just Good Arguments: Be Mindful of Tone and Structure!

A Must-see for Researchers! How to Ensure Inclusivity in Your Scientific Writing

Make Hook, Line, and Sinker: The Art of Crafting Engaging Introductions

Can Describing Study Limitations Improve the Quality of Your Paper?

A Guide to Crafting Shorter, Impactful Sentences in Academic Writing

6 Steps to Write an Excellent Discussion in Your Manuscript

How to Write Clear and Crisp Civil Engineering Papers? Here are 5 Key Tips to Consider
Input your search keywords and press Enter.
What Is A Research (Scientific) Hypothesis? A plain-language explainer + examples
By: Derek Jansen (MBA) | Reviewed By: Dr Eunice Rautenbach | June 2020
If you’re new to the world of research, or it’s your first time writing a dissertation or thesis, you’re probably noticing that the words “research hypothesis” and “scientific hypothesis” are used quite a bit, and you’re wondering what they mean in a research context .
“Hypothesis” is one of those words that people use loosely, thinking they understand what it means. However, it has a very specific meaning within academic research. So, it’s important to understand the exact meaning before you start hypothesizing.
Research Hypothesis 101
- What is a hypothesis ?
- What is a research hypothesis (scientific hypothesis)?
- Requirements for a research hypothesis
- Definition of a research hypothesis
- The null hypothesis
What is a hypothesis?
Let’s start with the general definition of a hypothesis (not a research hypothesis or scientific hypothesis), according to the Cambridge Dictionary:
Hypothesis: an idea or explanation for something that is based on known facts but has not yet been proved.
In other words, it’s a statement that provides an explanation for why or how something works, based on facts (or some reasonable assumptions), but that has not yet been specifically tested . For example, a hypothesis might look something like this:
Hypothesis: sleep impacts academic performance.
This statement predicts that academic performance will be influenced by the amount and/or quality of sleep a student engages in – sounds reasonable, right? It’s based on reasonable assumptions , underpinned by what we currently know about sleep and health (from the existing literature). So, loosely speaking, we could call it a hypothesis, at least by the dictionary definition.
But that’s not good enough…
Unfortunately, that’s not quite sophisticated enough to describe a research hypothesis (also sometimes called a scientific hypothesis), and it wouldn’t be acceptable in a dissertation, thesis or research paper . In the world of academic research, a statement needs a few more criteria to constitute a true research hypothesis .
What is a research hypothesis?
A research hypothesis (also called a scientific hypothesis) is a statement about the expected outcome of a study (for example, a dissertation or thesis). To constitute a quality hypothesis, the statement needs to have three attributes – specificity , clarity and testability .
Let’s take a look at these more closely.
Need a helping hand?
Hypothesis Essential #1: Specificity & Clarity
A good research hypothesis needs to be extremely clear and articulate about both what’ s being assessed (who or what variables are involved ) and the expected outcome (for example, a difference between groups, a relationship between variables, etc.).
Let’s stick with our sleepy students example and look at how this statement could be more specific and clear.
Hypothesis: Students who sleep at least 8 hours per night will, on average, achieve higher grades in standardised tests than students who sleep less than 8 hours a night.
As you can see, the statement is very specific as it identifies the variables involved (sleep hours and test grades), the parties involved (two groups of students), as well as the predicted relationship type (a positive relationship). There’s no ambiguity or uncertainty about who or what is involved in the statement, and the expected outcome is clear.
Contrast that to the original hypothesis we looked at – “Sleep impacts academic performance” – and you can see the difference. “Sleep” and “academic performance” are both comparatively vague , and there’s no indication of what the expected relationship direction is (more sleep or less sleep). As you can see, specificity and clarity are key.

Hypothesis Essential #2: Testability (Provability)
A statement must be testable to qualify as a research hypothesis. In other words, there needs to be a way to prove (or disprove) the statement. If it’s not testable, it’s not a hypothesis – simple as that.
For example, consider the hypothesis we mentioned earlier:
Hypothesis: Students who sleep at least 8 hours per night will, on average, achieve higher grades in standardised tests than students who sleep less than 8 hours a night.
We could test this statement by undertaking a quantitative study involving two groups of students, one that gets 8 or more hours of sleep per night for a fixed period, and one that gets less. We could then compare the standardised test results for both groups to see if there’s a statistically significant difference.
Again, if you compare this to the original hypothesis we looked at – “Sleep impacts academic performance” – you can see that it would be quite difficult to test that statement, primarily because it isn’t specific enough. How much sleep? By who? What type of academic performance?
So, remember the mantra – if you can’t test it, it’s not a hypothesis 🙂

Defining A Research Hypothesis
You’re still with us? Great! Let’s recap and pin down a clear definition of a hypothesis.
A research hypothesis (or scientific hypothesis) is a statement about an expected relationship between variables, or explanation of an occurrence, that is clear, specific and testable.
So, when you write up hypotheses for your dissertation or thesis, make sure that they meet all these criteria. If you do, you’ll not only have rock-solid hypotheses but you’ll also ensure a clear focus for your entire research project.
What about the null hypothesis?
You may have also heard the terms null hypothesis , alternative hypothesis, or H-zero thrown around. At a simple level, the null hypothesis is the counter-proposal to the original hypothesis.
For example, if the hypothesis predicts that there is a relationship between two variables (for example, sleep and academic performance), the null hypothesis would predict that there is no relationship between those variables.
At a more technical level, the null hypothesis proposes that no statistical significance exists in a set of given observations and that any differences are due to chance alone.
And there you have it – hypotheses in a nutshell.
If you have any questions, be sure to leave a comment below and we’ll do our best to help you. If you need hands-on help developing and testing your hypotheses, consider our private coaching service , where we hold your hand through the research journey.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
17 Comments

Very useful information. I benefit more from getting more information in this regard.

Very great insight,educative and informative. Please give meet deep critics on many research data of public international Law like human rights, environment, natural resources, law of the sea etc

In a book I read a distinction is made between null, research, and alternative hypothesis. As far as I understand, alternative and research hypotheses are the same. Can you please elaborate? Best Afshin

This is a self explanatory, easy going site. I will recommend this to my friends and colleagues.

Very good definition. How can I cite your definition in my thesis? Thank you. Is nul hypothesis compulsory in a research?

It’s a counter-proposal to be proven as a rejection

Please what is the difference between alternate hypothesis and research hypothesis?

It is a very good explanation. However, it limits hypotheses to statistically tasteable ideas. What about for qualitative researches or other researches that involve quantitative data that don’t need statistical tests?

In qualitative research, one typically uses propositions, not hypotheses.

could you please elaborate it more

I’ve benefited greatly from these notes, thank you.

This is very helpful

well articulated ideas are presented here, thank you for being reliable sources of information

Excellent. Thanks for being clear and sound about the research methodology and hypothesis (quantitative research)
I have only a simple question regarding the null hypothesis. – Is the null hypothesis (Ho) known as the reversible hypothesis of the alternative hypothesis (H1? – How to test it in academic research?

this is very important note help me much more

Hi” best wishes to you and your very nice blog”
Trackbacks/Pingbacks
- What Is Research Methodology? Simple Definition (With Examples) - Grad Coach - […] Contrasted to this, a quantitative methodology is typically used when the research aims and objectives are confirmatory in nature. For example,…
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly

Ed Tech as Applied Research: A Framework in Seven Hypotheses
Key takeaways.
- Seven hypotheses explore the feasibility of educational technology — typically considered as supporting teaching and learning — as applied research by providing an initial framework built on traditional research processes.
- New knowledge results from research , usually about fundamental questions, but ed tech pursues applied research about practical problems using qualitative and quantitative methods and local standards.
- Seeing ed tech as research emphasizes the collaborative nature of our work by helping shape our conversations about the knowledge we create, its standards, and its methods.
Edward R. O'Neill, Senior Instructional Designer, Yale University
Those of us who provide educational technology services may see ourselves in many different frameworks: as IT service providers, as resources to be allocated, as technology experts, as support staff — to name only a few. I might be troubleshooting, tinkering, keeping clients happy, performing one of my job duties, or solving problems, easy and hard.
We may also see ourselves as part of human services more broadly, supporting human agency and growth. However we think about this, we support the university’s mission — and by extension some of our culture’s loftiest goals. Teachers teach, learners learn, and educational technologists support their teaching and learning: the dissemination of knowledge to students. But what of knowledge's creation and dissemination beyond our institutions' walls? What relation does ed tech bear to research and publication?
Much has been said and written about ed tech as a service. The framework offered here sees ed tech as scholarship and draws practical consequences from this way of seeing. To explore the aptness of this framework, I offer the following seven hypotheses.
1. Ed tech supports and replicates the university's mission, using the methods characteristic of scholarship in general and research in particular.
We who work in educational technology support the university's mission to preserve, create, and disseminate knowledge. The university disseminates knowledge through a range of activities from publication to teaching, and ed tech's special role is to support the teaching part, although no hard line separates sharing knowledge with scholars, students, and the general public.
To support this mission, ed tech must pursue its own, smaller, practical version of the university's mission.
- We must gather and keep, discover and share knowledge about educational technology so that we can recommend the right tool for each task and support these tools effectively and efficiently.
- Like other forms of research, we must do this transparently, using standards that evolve through discussion and experience.
- Even supporting the tools we recommend involves disseminating knowledge: helping faculty and students learn to use these tools (or others of their choosing) is itself a kind of teaching.
In short, ed tech is research and teaching of an applied and local sort.
Our knowledge in ed tech is practical : it aims to solve immediate problems. One key practical problem we face is, What is the best tool to achieve a specific goal? (Ed tech fits means to ends.) Answering this kind of question is perfectly feasible using methods native to higher education. When we hew to the methods and values of higher ed, we draw closer to those we serve: the faculty. We come to understand faculty better, as they do us, by sharing common values, methods, and habits of mind and of doing — we form a community.
In higher ed, new knowledge results from a process called research . But where scientists and scholars in higher ed usually pursue basic research about fundamental questions using precise methods and widely shared disciplinary standards, in educational technology, we pursue applied research about practical problems using a variety of general methods and standards that are on the one hand professional and on the other hand local and institutional.
Said differently, educational technology is applied research using mixed methods and local standards.
2. Ed tech work fits into the three phases of the research process.
Our ways of creating ed tech knowledge map well onto the methods used in higher education for research. Broadly construed, research involves three main phases: exploring , defining , and testing . The testing process is often construed as hypothesis testing . Whether they're scientists or humanists, scholars explore a problem, define its terms, and then develop testable hypotheses. When we in ed tech know the phase of research we have reached and what hypotheses we want to test, it's easier to track our progress, regularize our work, and target an explicit and shared set of standards –– all things we must do to be effective, efficient, and transparent members of our communities.
An example is helpful. In sociology, Erving Goffman either created or inspired a new approach (variously called the dramaturgical approach, ethnomethodology, conversational analysis, or discourse analysis) by the way he explored, defined, and tested a specific phenomenon. 1
- Exploring. Goffman was curious about why people interact the way they do. Why do they talk this way or that, wear these clothes or those in specific contexts, such as a rural village or a psychiatric hospital?
- Defining . Goffman saw these questions as problems of "social order": how do people organize their actions and interactions? Goffman extended this traditional area in sociology to the micro-level of small gestures and ways of speaking. He defined his research as answering the question "How is social order maintained?"
- Testing and Hypothesis Testing. For the purposes of testing, Goffman collected observational data about face-to-face social interactions and behavioral reports from memoirs and newspapers. He also recorded conversations and analyzed the transcripts. Goffman developed specific explanations (his hypotheses), and then "tested" them against his collected observations, reports, and transcripts.
In ed tech, we also explore, define, and test. Our explorations revolve around practices, however.
- Exploring. What tools are people using? For what purposes? With what results? Here and elsewhere?
- Defining. What kinds of tools and functions are involved? What kinds of purposes? For example, is videoconferencing good for collaboration? For assessment? For rehearsal and feedback?
For these two phases of research we draw on the work of our colleagues at other institutions, as well as that of researchers in the areas of education, psychology, organizational behavior, and more.
When it comes to tools and learning processes, our categories need to be useful and shareable, parsimonious and rigorous without becoming abstract. We can't speak our own private language, nor a recondite professional jargon. We need few enough categories to avoid being overwhelmed, and we need clear lines to avoid becoming theological.
- Testing. Finally, we need to test the tools and verify that they work well enough for the purposes at hand. This requires asking, does this tool do what people say? Reliably? Is it usable enough to hand off to instructors and students? Is it so complex that the support time will eat us alive? What evidence do we have, and how sure are we of that evidence?
Calling what we do "research" does not imply we need a controlled double-blind study to confirm what we know: We need to be sure that we are effective and that the degree of certainty escalates with the investment of time, labor, and money.
From another angle, ed tech as research is akin to scientific teaching as a process that constantly tests its own effectiveness as a kind of hypothesis testing. Ed tech activity of this kind will also support scientific teaching better because it not only "walks the walk," it makes us better at practical hypothesis testing.
3. Ed tech can use familiar research methods as well as a broad understanding of learning.
Our methods are both qualitative and quantitative — in a word, mixed. We collect both numbers and descriptions. Our toolkit should encompass a range, including these basic tools:
- Literature review: reading research and publications about others' practices, experiences, and results
- Interviews: calling, e-mailing, and chatting with faculty and students
- Statistics: counting what we do, hear, and see
- Field experiments: testing of a tool by professors to see how it works for them
- Equipment calibration and testing: using the tool ourselves to see if it works to our standards
- Natural experiments: finding similar situations that use different approaches to create a semi-controlled experiment
- Observational studies: watching teachers and learners at work to discover what happens with interesting tools "in the wild"
- Ethnographies: interviewing users and capturing the data as audio, video, or notes in order to get a rich account of the experience of teaching or learning with a specific tool
- Semi-controlled experiments: finding two similar classes or sections, one using a tool and the other not (or using a different tool)
- Meta-analyses: comparing the results of disparate research studies or our own observations
Some research methods fit better in one phase of the research process than do others. Each phase also has its key activities: verbs that further specify the acts of exploration and definition.
| Phase | Activities | Research Methods |
|---|---|---|
| EXPLORE | Observe Collect Summarize Record | Lit review Interview Field experiments Natural experiment Observational studies |
| DEFINE | Characterize Analyze Categorize | Lit review Debate Professional norms |
| TEST | Check Verify Measure Correlate Compare | Testing Observational studies Interviews Controlled experiments |
Since our research is about how tools fit purposes, we need some notions about the purpose of ed tech: supporting learning. Without committing to one specific theory of learning, we can specify four elements that help define semi-agnostically how we see learning: what it is, how it unfolds in time, and big and small ways to enable it.
- Basic definitions. What is learning itself? What are the main frameworks that have been used effectively to understand and support learning? E.g., goal orientation, motivation, working memory.
- Process elements. What are the important moments in the instructional process? E.g., defining the learning objective, the student practicing or rehearsing and getting feedback, assessing whether the student has learned, etc.
- Whole strategies. What instructional strategies have been found effective? E.g., authentic learning, problem-based learning, inquiry-based learning.
- Valued supportive behaviors. What activities that are deeply valued in the context of higher education support learning? E.g., collaboration, writing, dialogue, and debate.
4. Knowing the phases of the research process lets us share where we are in that process for any given set of tools.
As we progress from exploring tools to defining their uses and testing them, we constantly gather and share our knowledge. Ideally, there is no single moment at which we suddenly need to know something precise without any background whatever. Instead, we will be most successful when we collect and share our knowledge gradually as we go, tracking where we are in the exploring, defining, testing process for each category of tools and purposes. If we do not know at any given moment what tools are used to support collaboration or assessment and how well they work for that purpose, then we will have a much harder time testing tools according to our own standards — which need to be explicit from the start, as well as constantly refined.
For each kind of tool and purpose, we should know which phase of the process of research (exploration, definition, testing) we have done, are in, and need to do . A robust system would map all our important dimensions against each other: phases, purposes, and tools. E.g.,
"These are the tools we're exploring, those are the tools we are testing, and here are the purposes we think they're good for."
"These are tools we have tested and that meet our standards, and here are the purposes we see them as fit for, along with our methods and evidence."
Not all tools are neatly focused toward specific ends. Some tools will likely be so basic that their purpose is merely utilitarian or back-end, such as file sharing, sending messages, or social interaction. Some megatools enfold many functions, such as the LMS, blogging platforms, and content management systems. These megatools support broadly valued activities in higher education. Ed tech knowledge about how tools fit purposes thus has a definite shape.
| Questions | Category |
|---|---|
| What is it? | Tools |
| What does it do? | live synchronous communication, multimedia production, etc. |
| Why would I need it? | specific teaching and learning, and more general activities of organizing and communicating |
| Does it work? | testing and the evidence we find and collect ourselves |
| How do I get it? | Availability |
| Who supports it? | Support |
The structure of our knowledge makes that knowledge amenable to gathering and sharing by various methods. But a good tool for managing this information would go a long way, and being experts in fitting tools to purposes, we will likely conclude that the tool that lets us track and share our knowledge is a robust but elegant content management system (CMS). Such a system would support a narrow range of utterances:
"This is a tool we are exploring/testing/have tested for this or that learning purpose." Tool, phase, and purpose. "This is information we have found about a specific tool from a specific research method: interview, lit review, observation, etc." Data, research method, tool, and purpose.
"Here is a reference to a specific tool we plan to explore, along with possible purposes."
Such a system would work as a kind of dashboard. It would also allow us to track our work internally and simultaneously publish whatever elements we are ready to share. Moving knowledge from system to system is inefficient, however, and when support comes first, sharing our knowledge will always take a back seat. Therefore the knowledge management system and the knowledge sharing system would ideally be one and the same.
Indeed, if efficiency is a paramount concern (as it should be), and the relevant resources are far-flung, then it would be easier to point to them than to gather them together — a bibliography, not an encyclopedia. Given that tools like delicious.com, Tumblr, Zotero, Instapaper, and Evernote, to name a few, point to information elsewhere or gather disparate resources in a single location, it's also possible that the CMS is overkill for ed tech knowledge tracking.
5. Ed tech verifies hypotheses of a few definite types.
In ed tech, our hypotheses have typical forms. For example:
- has functions F(1…n)
- works well enough to be recommended and supported according to standards S(1…n), and
- supports purposes P(1…n).
Our work on the first level is verification . We assure ourselves that Tool T really has the functions claimed. Hypotheses start out basic and increase in complexity of the evaluative criteria we use. There is no point in testing the functions of a tool that does not work on the platforms you need it to run on. What operating systems are supported? Functions required must then be identified for testing on the relevant operating systems.
Our work on the next two levels is (1) discovery and (2) verification and evaluation. We find out how well the tool works, verify existing claims, and evaluate the facts we gather based on our local framework of needs and standards.
6. Well-formed ed tech recommendations are sourced, supported, and qualified.
Recommendations will be more compelling when they carry with them the sources of our authority: our research methods and evidence. Recommendations cannot be unqualified, however; there are always caveats.
Here it seems wise to label the tools we recommend in terms of the level of support faculty and students can expect. Three levels seem crucial.
- This is a tool or service our institution bought or made. We support it, and the vendor has promised a certain level of support. Changes can be made as needed based on institutional priorities.
- This is a tool or service our institution pays for. The vendor supports it, but we do not. Changes can only be made by the vendor on their own timeframe.
- This is a tool or service our institution does not buy or pay for. There is no promise of support. Use should be considered at your own risk, except that we evaluate all recommended tools for certain basic needs, such as security and data portability.
7. Piloting is a kind of testing and evaluation based on strategic criteria.
A pilot is one kind of testing. But piloting typically only happens when a decision is to be made about the relative value of buying or supporting a specific tool for a specific purpose. When we decide to recommend and support a tool, even given all the proper caveats, such a recommendation comes with a cost: even if no money is spent, time and therefore money are used up. When such expenditures, whether in labor or dollars, rise above a certain threshold, a special kind of evaluation is needed. The criteria of such an evaluation are largely strategic:
- What is the potential impact in depth and in breadth?
- How innovative is the tool or activity?
- Does it fit with our strategic goals?
- Does it meet our standards of data integrity, security, portability, etc.?
- How easy or difficult is it to support? How labor-intensive?
- Does it fit with our infrastructure?
The hypothesis involved has a characteristic form: "Tool T meets our standards for recommendation and support." The form is trivial; the devil is in the standards.
One possible set of standards follows; bigger and smaller schools will have different values when counting impact.
| Dimension/ | Depth of Impact | Breadth of Impact | Level of Innovation | Alignment with Goals | Attention Likely |
|---|---|---|---|---|---|
| Strong | Impacts over 1,000 students in a single academic year. | Benefits an entire school or program. | Represents a quantum leap for us and puts us at the top of our peer institutions. | Aligns with at least two strategic goals at three different levels: the profession, the university, our unit, the relevant schools and departments | Likely to attract positive attention. |
| Moderate | Impacts over 100 and under 1,000 students in a single academic year. | Benefits several professors or a department. | Represents an incremental advance or brings us up to the level of our peers. | Aligns with at least two strategic goals at two different levels: the profession, the university, our unit, the relevant schools and departments. | Likely to attract mixed attention. |
| Weak | Impacts under 100 students in a single academic year. | Benefits one professor. | Represents the status quo for our institution. | Does not clearly align with any of the relevant strategic goals: the profession, the university, our unit, the relevant schools and departments. | Likely to attract negative attention |
To what extent breadth of impact, say, outweighs potential negative attention is something to decide in practice. Having a clear set of standards absolves no-one from making judgment calls. After enough evaluations have been completed using an instrument like this one, it should be possible to set the borderlines more clearly and even to weight the factors so that, for instance, insufficient documentation is a deal-breaker and possible negative attention is merely a nuisance — or vice-versa.
Concluding Observations
The verification of these hypotheses can only come through practice. To the extent that any part of them cannot be verified, that part needs to be thrown away and the hypothesis adjusted accordingly. The preceding is not just a framework and hypotheses: as research, it's a call to a community to share and discuss results, evidence, and methods. Although our work is always local, case-based reasoning will suggest analogies even for those whose work seems on the surface far-flung. Research is future-oriented and remains forever open. I offer this framework in that spirit.
Acknowledgments
My thanks go to my supervisor at Yale University, Edward Kairiss. He asked me to reflect on what a “pilot” was, and when I found that I needed to step back and get a wider view, not only did he not balk, he encouraged me. What is written here would not exist without his encouragement and support. Additional thanks go to David Hirsch, whose organizational work at Yale provided a model of what the reflective practitioner can accomplish.
- Peter Chilson, "The Border," in The Best American Travel Writing 2008 , ed. Anthony Bourdain (Boston: Houghton Mifflin Company, 2008), 44–51; Michael Hviid Jacobsen, "Reading Goffman 'Forward,'" in The Social Thought of Erving Goffman , eds. Michael Hviid Jacobsen and Soren Kristiansen (London: Sage, 2014), 147–159; and Emanuel A. Schlegloff, "Goffman and the Analysis of Conversation," in Erving Goffman: Exploring the Interaction Order , eds. Paul Drew and Anthony Wootton (Cambridge, UK: Polity Press, 1988), 89–93.
© 2015 Edward R. O'Neill. The text of this EDUCAUSE Review article is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs 4.0 license .
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case AskWhy Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Research Hypothesis: What It Is, Types + How to Develop?

A research study starts with a question. Researchers worldwide ask questions and create research hypotheses. The effectiveness of research relies on developing a good research hypothesis. Examples of research hypotheses can guide researchers in writing effective ones.
In this blog, we’ll learn what a research hypothesis is, why it’s important in research, and the different types used in science. We’ll also guide you through creating your research hypothesis and discussing ways to test and evaluate it.
What is a Research Hypothesis?
A hypothesis is like a guess or idea that you suggest to check if it’s true. A research hypothesis is a statement that brings up a question and predicts what might happen.
It’s really important in the scientific method and is used in experiments to figure things out. Essentially, it’s an educated guess about how things are connected in the research.
A research hypothesis usually includes pointing out the independent variable (the thing they’re changing or studying) and the dependent variable (the result they’re measuring or watching). It helps plan how to gather and analyze data to see if there’s evidence to support or deny the expected connection between these variables.
Importance of Hypothesis in Research
Hypotheses are really important in research. They help design studies, allow for practical testing, and add to our scientific knowledge. Their main role is to organize research projects, making them purposeful, focused, and valuable to the scientific community. Let’s look at some key reasons why they matter:
- A research hypothesis helps test theories.
A hypothesis plays a pivotal role in the scientific method by providing a basis for testing existing theories. For example, a hypothesis might test the predictive power of a psychological theory on human behavior.
- It serves as a great platform for investigation activities.
It serves as a launching pad for investigation activities, which offers researchers a clear starting point. A research hypothesis can explore the relationship between exercise and stress reduction.
- Hypothesis guides the research work or study.
A well-formulated hypothesis guides the entire research process. It ensures that the study remains focused and purposeful. For instance, a hypothesis about the impact of social media on interpersonal relationships provides clear guidance for a study.
- Hypothesis sometimes suggests theories.
In some cases, a hypothesis can suggest new theories or modifications to existing ones. For example, a hypothesis testing the effectiveness of a new drug might prompt a reconsideration of current medical theories.
- It helps in knowing the data needs.
A hypothesis clarifies the data requirements for a study, ensuring that researchers collect the necessary information—a hypothesis guiding the collection of demographic data to analyze the influence of age on a particular phenomenon.
- The hypothesis explains social phenomena.
Hypotheses are instrumental in explaining complex social phenomena. For instance, a hypothesis might explore the relationship between economic factors and crime rates in a given community.
- Hypothesis provides a relationship between phenomena for empirical Testing.
Hypotheses establish clear relationships between phenomena, paving the way for empirical testing. An example could be a hypothesis exploring the correlation between sleep patterns and academic performance.
- It helps in knowing the most suitable analysis technique.
A hypothesis guides researchers in selecting the most appropriate analysis techniques for their data. For example, a hypothesis focusing on the effectiveness of a teaching method may lead to the choice of statistical analyses best suited for educational research.
Characteristics of a Good Research Hypothesis
A hypothesis is a specific idea that you can test in a study. It often comes from looking at past research and theories. A good hypothesis usually starts with a research question that you can explore through background research. For it to be effective, consider these key characteristics:
- Clear and Focused Language: A good hypothesis uses clear and focused language to avoid confusion and ensure everyone understands it.
- Related to the Research Topic: The hypothesis should directly relate to the research topic, acting as a bridge between the specific question and the broader study.
- Testable: An effective hypothesis can be tested, meaning its prediction can be checked with real data to support or challenge the proposed relationship.
- Potential for Exploration: A good hypothesis often comes from a research question that invites further exploration. Doing background research helps find gaps and potential areas to investigate.
- Includes Variables: The hypothesis should clearly state both the independent and dependent variables, specifying the factors being studied and the expected outcomes.
- Ethical Considerations: Check if variables can be manipulated without breaking ethical standards. It’s crucial to maintain ethical research practices.
- Predicts Outcomes: The hypothesis should predict the expected relationship and outcome, acting as a roadmap for the study and guiding data collection and analysis.
- Simple and Concise: A good hypothesis avoids unnecessary complexity and is simple and concise, expressing the essence of the proposed relationship clearly.
- Clear and Assumption-Free: The hypothesis should be clear and free from assumptions about the reader’s prior knowledge, ensuring universal understanding.
- Observable and Testable Results: A strong hypothesis implies research that produces observable and testable results, making sure the study’s outcomes can be effectively measured and analyzed.
When you use these characteristics as a checklist, it can help you create a good research hypothesis. It’ll guide improving and strengthening the hypothesis, identifying any weaknesses, and making necessary changes. Crafting a hypothesis with these features helps you conduct a thorough and insightful research study.
Types of Research Hypotheses
The research hypothesis comes in various types, each serving a specific purpose in guiding the scientific investigation. Knowing the differences will make it easier for you to create your own hypothesis. Here’s an overview of the common types:
01. Null Hypothesis
The null hypothesis states that there is no connection between two considered variables or that two groups are unrelated. As discussed earlier, a hypothesis is an unproven assumption lacking sufficient supporting data. It serves as the statement researchers aim to disprove. It is testable, verifiable, and can be rejected.
For example, if you’re studying the relationship between Project A and Project B, assuming both projects are of equal standard is your null hypothesis. It needs to be specific for your study.
02. Alternative Hypothesis
The alternative hypothesis is basically another option to the null hypothesis. It involves looking for a significant change or alternative that could lead you to reject the null hypothesis. It’s a different idea compared to the null hypothesis.
When you create a null hypothesis, you’re making an educated guess about whether something is true or if there’s a connection between that thing and another variable. If the null view suggests something is correct, the alternative hypothesis says it’s incorrect.
For instance, if your null hypothesis is “I’m going to be $1000 richer,” the alternative hypothesis would be “I’m not going to get $1000 or be richer.”
03. Directional Hypothesis
The directional hypothesis predicts the direction of the relationship between independent and dependent variables. They specify whether the effect will be positive or negative.
If you increase your study hours, you will experience a positive association with your exam scores. This hypothesis suggests that as you increase the independent variable (study hours), there will also be an increase in the dependent variable (exam scores).
04. Non-directional Hypothesis
The non-directional hypothesis predicts the existence of a relationship between variables but does not specify the direction of the effect. It suggests that there will be a significant difference or relationship, but it does not predict the nature of that difference.
For example, you will find no notable difference in test scores between students who receive the educational intervention and those who do not. However, once you compare the test scores of the two groups, you will notice an important difference.
05. Simple Hypothesis
A simple hypothesis predicts a relationship between one dependent variable and one independent variable without specifying the nature of that relationship. It’s simple and usually used when we don’t know much about how the two things are connected.
For example, if you adopt effective study habits, you will achieve higher exam scores than those with poor study habits.
06. Complex Hypothesis
A complex hypothesis is an idea that specifies a relationship between multiple independent and dependent variables. It is a more detailed idea than a simple hypothesis.
While a simple view suggests a straightforward cause-and-effect relationship between two things, a complex hypothesis involves many factors and how they’re connected to each other.
For example, when you increase your study time, you tend to achieve higher exam scores. The connection between your study time and exam performance is affected by various factors, including the quality of your sleep, your motivation levels, and the effectiveness of your study techniques.
If you sleep well, stay highly motivated, and use effective study strategies, you may observe a more robust positive correlation between the time you spend studying and your exam scores, unlike those who may lack these factors.
07. Associative Hypothesis
An associative hypothesis proposes a connection between two things without saying that one causes the other. Basically, it suggests that when one thing changes, the other changes too, but it doesn’t claim that one thing is causing the change in the other.
For example, you will likely notice higher exam scores when you increase your study time. You can recognize an association between your study time and exam scores in this scenario.
Your hypothesis acknowledges a relationship between the two variables—your study time and exam scores—without asserting that increased study time directly causes higher exam scores. You need to consider that other factors, like motivation or learning style, could affect the observed association.
08. Causal Hypothesis
A causal hypothesis proposes a cause-and-effect relationship between two variables. It suggests that changes in one variable directly cause changes in another variable.
For example, when you increase your study time, you experience higher exam scores. This hypothesis suggests a direct cause-and-effect relationship, indicating that the more time you spend studying, the higher your exam scores. It assumes that changes in your study time directly influence changes in your exam performance.
09. Empirical Hypothesis
An empirical hypothesis is a statement based on things we can see and measure. It comes from direct observation or experiments and can be tested with real-world evidence. If an experiment proves a theory, it supports the idea and shows it’s not just a guess. This makes the statement more reliable than a wild guess.
For example, if you increase the dosage of a certain medication, you might observe a quicker recovery time for patients. Imagine you’re in charge of a clinical trial. In this trial, patients are given varying dosages of the medication, and you measure and compare their recovery times. This allows you to directly see the effects of different dosages on how fast patients recover.
This way, you can create a research hypothesis: “Increasing the dosage of a certain medication will lead to a faster recovery time for patients.”
10. Statistical Hypothesis
A statistical hypothesis is a statement or assumption about a population parameter that is the subject of an investigation. It serves as the basis for statistical analysis and testing. It is often tested using statistical methods to draw inferences about the larger population.
In a hypothesis test, statistical evidence is collected to either reject the null hypothesis in favor of the alternative hypothesis or fail to reject the null hypothesis due to insufficient evidence.
For example, let’s say you’re testing a new medicine. Your hypothesis could be that the medicine doesn’t really help patients get better. So, you collect data and use statistics to see if your guess is right or if the medicine actually makes a difference.
If the data strongly shows that the medicine does help, you say your guess was wrong, and the medicine does make a difference. But if the proof isn’t strong enough, you can stick with your original guess because you didn’t get enough evidence to change your mind.
How to Develop a Research Hypotheses?
Step 1: identify your research problem or topic..
Define the area of interest or the problem you want to investigate. Make sure it’s clear and well-defined.
Start by asking a question about your chosen topic. Consider the limitations of your research and create a straightforward problem related to your topic. Once you’ve done that, you can develop and test a hypothesis with evidence.
Step 2: Conduct a literature review
Review existing literature related to your research problem. This will help you understand the current state of knowledge in the field, identify gaps, and build a foundation for your hypothesis. Consider the following questions:
- What existing research has been conducted on your chosen topic?
- Are there any gaps or unanswered questions in the current literature?
- How will the existing literature contribute to the foundation of your research?
Step 3: Formulate your research question
Based on your literature review, create a specific and concise research question that addresses your identified problem. Your research question should be clear, focused, and relevant to your field of study.
Step 4: Identify variables
Determine the key variables involved in your research question. Variables are the factors or phenomena that you will study and manipulate to test your hypothesis.
- Independent Variable: The variable you manipulate or control.
- Dependent Variable: The variable you measure to observe the effect of the independent variable.
Step 5: State the Null hypothesis
The null hypothesis is a statement that there is no significant difference or effect. It serves as a baseline for comparison with the alternative hypothesis.
Step 6: Select appropriate methods for testing the hypothesis
Choose research methods that align with your study objectives, such as experiments, surveys, or observational studies. The selected methods enable you to test your research hypothesis effectively.
Creating a research hypothesis usually takes more than one try. Expect to make changes as you collect data. It’s normal to test and say no to a few hypotheses before you find the right answer to your research question.
Testing and Evaluating Hypotheses
Testing hypotheses is a really important part of research. It’s like the practical side of things. Here, real-world evidence will help you determine how different things are connected. Let’s explore the main steps in hypothesis testing:
- State your research hypothesis.
Before testing, clearly articulate your research hypothesis. This involves framing both a null hypothesis, suggesting no significant effect or relationship, and an alternative hypothesis, proposing the expected outcome.
- Collect data strategically.
Plan how you will gather information in a way that fits your study. Make sure your data collection method matches the things you’re studying.
Whether through surveys, observations, or experiments, this step demands precision and adherence to the established methodology. The quality of data collected directly influences the credibility of study outcomes.
- Perform an appropriate statistical test.
Choose a statistical test that aligns with the nature of your data and the hypotheses being tested. Whether it’s a t-test, chi-square test, ANOVA, or regression analysis, selecting the right statistical tool is paramount for accurate and reliable results.
- Decide if your idea was right or wrong.
Following the statistical analysis, evaluate the results in the context of your null hypothesis. You need to decide if you should reject your null hypothesis or not.
- Share what you found.
When discussing what you found in your research, be clear and organized. Say whether your idea was supported or not, and talk about what your results mean. Also, mention any limits to your study and suggest ideas for future research.
The Role of QuestionPro to Develop a Good Research Hypothesis
QuestionPro is a survey and research platform that provides tools for creating, distributing, and analyzing surveys. It plays a crucial role in the research process, especially when you’re in the initial stages of hypothesis development. Here’s how QuestionPro can help you to develop a good research hypothesis:
- Survey design and data collection: You can use the platform to create targeted questions that help you gather relevant data.
- Exploratory research: Through surveys and feedback mechanisms on QuestionPro, you can conduct exploratory research to understand the landscape of a particular subject.
- Literature review and background research: QuestionPro surveys can collect sample population opinions, experiences, and preferences. This data and a thorough literature evaluation can help you generate a well-grounded hypothesis by improving your research knowledge.
- Identifying variables: Using targeted survey questions, you can identify relevant variables related to their research topic.
- Testing assumptions: You can use surveys to informally test certain assumptions or hypotheses before formalizing a research hypothesis.
- Data analysis tools: QuestionPro provides tools for analyzing survey data. You can use these tools to identify the collected data’s patterns, correlations, or trends.
- Refining your hypotheses: As you collect data through QuestionPro, you can adjust your hypotheses based on the real-world responses you receive.
A research hypothesis is like a guide for researchers in science. It’s a well-thought-out idea that has been thoroughly tested. This idea is crucial as researchers can explore different fields, such as medicine, social sciences, and natural sciences. The research hypothesis links theories to real-world evidence and gives researchers a clear path to explore and make discoveries.
QuestionPro Research Suite is a helpful tool for researchers. It makes creating surveys, collecting data, and analyzing information easily. It supports all kinds of research, from exploring new ideas to forming hypotheses. With a focus on using data, it helps researchers do their best work.
Are you interested in learning more about QuestionPro Research Suite? Take advantage of QuestionPro’s free trial to get an initial look at its capabilities and realize the full potential of your research efforts.
LEARN MORE FREE TRIAL
MORE LIKE THIS

Net Trust Score: Tool for Measuring Trust in Organization
Sep 2, 2024

Why You Should Attend XDAY 2024
Aug 30, 2024

Alchemer vs Qualtrics: Find out which one you should choose

Target Population: What It Is + Strategies for Targeting
Aug 29, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Tuesday CX Thoughts (TCXT)
- Uncategorized
- What’s Coming Up
- Workforce Intelligence
Comparative Hypotheses for Technology Analysis
- Living reference work entry
- First Online: 19 June 2020
- Cite this living reference work entry

- Mario Coccia 2 , 3
Nature of technology ; Technology ; Technological innovation ; Technological evolution ; Technological change ; Technological progress ; Technological advances
Hypothesis refers to a supposition put forward in a provisional manner and in need of further epistemic and empirical support. Technology analysis explains the relationships underlying the source, evolution, and diffusion of technology for technological, economic and social change. Technology analysis considers technology as a complex system that evolves with incremental and radical innovations to satisfy needs, achieve goals, and/or solve problems of adopters to take advantage of important opportunities or to cope with consequential environmental threats.
Introduction
Technology has an important role for competitive advantage of firms and nations, for industrial and economic change in society (Arthur 2009 ; Hosler 1994 ; Sahal 1981 ). Technology can be defined as a complex system, composed of more than one entity or...
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Institutional subscriptions
Ahmad S (1966) On the theory of induced innovation. Econ J 76:344–57
Google Scholar
Arthur WB (1989) Competing technologies, increasing returns, and lock-in by historical events. Econ J 99:116–131
Article Google Scholar
Arthur WB (1994) Increasing returns and path dependence in the economy. University of Michigan Press, Ann Arbor
Book Google Scholar
Arthur BW (2009) The nature of technology. What it is and how it evolves. Allen Lane–Penguin Books, London
Binswanger HP (1974) A cost function approach to the measurement of elasticities of factor demand and elasticities of substitution. Am J Agric Econ 56:377–386
Binswanger HP, Ruttan VW (1978) Induced innovation: technology, institutions and development. Johns Hopkins University Press, Baltimore
Chamberlin TC (1897) The method of multiple working hypotheses. J Geol 5(8):837–848
Coccia M (2005a) Metrics to measure the technology transfer absorption: analysis of the relationship between institutes and adopters in northern Italy. Int J Technol Transf Commer 4(4):462–486. https://doi.org/10.1504/IJTTC.2005.006699
Coccia M (2005b) Measuring intensity of technological change: the seismic approach. Technol Forecast Soc Chang 72(2):117–144. https://doi.org/10.1016/j.techfore.2004.01.004
Coccia M (2005c) A taxonomy of public research bodies: a systemic approach. Prometheus 23(1):63–82. https://doi.org/10.1080/0810902042000331322
Coccia M (2006a) Analysis and classification of public research institutes, world review of science. Technol Sustain Dev 3(1):1–16. https://doi.org/10.1504/WRSTSD.2006.008759
Coccia M (2006b) Classifications of innovations: survey and future directions. Working Paper Ceris del Consiglio Nazionale delle Ricerche, Ceris-Cnr Working Paper, vol 8, no 2 – ISSN (Print): 1591-0709. Available at arXiv Open access e-prints: http://arxiv.org/abs/1705.08955
Coccia M (2010) Democratization is the driving force for technological and economic change. Technol Forecast Soc Chang 77(2):248–264. https://doi.org/10.1016/j.techfore.2009.06.007
Coccia M (2014a) Driving forces of technological change: the relation between population growth and technological innovation-analysis of the optimal interaction across countries. Technol Forecast Soc Chang 82(2):52–65. https://doi.org/10.1016/j.techfore.2013.06.001
Coccia M (2014b) Path-breaking target therapies for lung cancer and a far-sighted health policy to support clinical and cost effectiveness. Health Policy Technol 1(3):74–82. https://doi.org/10.1016/j.hlpt.2013.09.007
Coccia M (2014c) Steel market and global trends of leading geo-economic players. Int J Trade Global Markets 7(1):36–52. http://doi.org/10.1504/IJTGM.2014.058714
Coccia M (2015a) General sources of general purpose technologies in complex societies: theory of global leadership-driven innovation, warfare and human development. Technol Soc 42:199–226. https://doi.org/10.1016/j.techsoc.2015.05.008
Coccia M (2015b) Technological paradigms and trajectories as determinants of the R&D corporate change in drug discovery industry. Int J Knowl Learn 10(1):29–43. https://doi.org/10.1504/IJKL.2015.071052
Coccia M (2015c) Spatial relation between geo-climate zones and technological outputs to explain the evolution of technology. Int J Transit Innovat Sys 4(1–2):5–21. http://doi.org/10.1504/IJTIS.2015.074642
Coccia M (2016a) Radical innovations as drivers of breakthroughs: characteristics and properties of the management of technology leading to superior organizational performance in the discovery process of R&D labs. Tech Anal Strat Manag 28(4):381–395. https://doi.org/10.1080/09537325.2015.1095287
Coccia M (2016b) The relation between price setting in markets and asymmetries of systems of measurement of goods. J Econ Asymmetr 14(Part B):168–178. https://doi.org/10.1016/j.jeca.2016.06.001
Coccia M (2016c) Problem-driven innovations in drug discovery: co-evolution of the patterns of radical innovation with the evolution of problems. Health Policy Technol 5(2):143–155. https://doi.org/10.1016/j.hlpt.2016.02.003
Coccia M (2017a) The fishbone diagram to identify, systematize and analyze the sources of general purpose technologies. J Adm Soc Sci 4(4):291–303. https://doi.org/10.1453/jsas.v4i4.1518
Coccia M (2017b) The source and nature of general purpose technologies for supporting next K-waves: global leadership and the case study of the U.S. Navy’s Mobile User Objective System. Technol Forecast Soc Chang 116:331–339. https://doi.org/10.1016/j.techfore.2016.05.019
Coccia M (2017c) Varieties of capitalism’s theory of innovation and a conceptual integration with leadership-oriented executives: the relation between typologies of executive, technological and socioeconomic performances. Int J Pub Se Perform Manage 3(2):148–168. https://doi.org/10.1504/IJPSPM.2017.084672
Coccia M (2017d) Disruptive firms and industrial change. J Econ Soc Thought 4(4):437–450. http://doi.org/10.1453/jest.v4i4.1511
Coccia M (2017e) Sources of disruptive technologies for industrial change. L’industria–rivista di economia e politica industriale 38(1):97–120
Coccia M (2018a) The origins of the economics of Innovation. J Econ Soc Thought 5(1):9–28, http://doi.org/10.1453/jest.v5i1.1574
Coccia M (2018b) Theorem of not independence of any technological innovation. J Econ Bibliogr 5(1):29–35. https://doi.org/10.1453/jeb.v5i1.1578
Coccia M (2019a) Comparative theories of the evolution of technology. In: Farazmand A (ed) Global Encyclopedia of public administration, public policy, and governance. Springer, Cham. https://doi.org/10.1007/978-3-319-31816-5_3841-1
Chapter Google Scholar
Coccia M (2019b) The theory of technological parasitism for the measurement of the evolution of technology and technological forecasting, Technol Forecast Soc Chang. https://doi.org/10.1016/j.techfore.2018.12.012
Coccia M (2019c) Killer technologies: the destructive creation in the technical change. ArXiv.org e-Print archive, Cornell University, USA. Permanent arXiv available at http://arxiv.org/abs/1907.12406
Coccia M (2019d) A theory of classification and evolution of technologies within a generalized Darwinism. Tech Anal Strat Manag 31(5):517–531. https://doi.org/10.1080/09537325.2018.1523385
Coccia M (2020) Deep learning technology for improving cancer care in society: new directions in cancer imaging driven by artificial intelligence. Technol Soc 60:1–11. https://doi.org/10.1016/j.techsoc.2019.101198
Coccia M, Benati I (2018) Comparative models of inquiry. In: Farazmand A (ed) Global encyclopedia of public administration, public policy, and governance. Springer International Publishing AG, part of Springer Nature. https://doi.org/10.1007/978-3-319-31816-5_1199-1
Coccia M, Wang L (2015) Path-breaking directions of nanotechnology-based chemotherapy and molecular cancer therapy. Technol Forecast Soc Chang 94:155–169. https://doi.org/10.1016/j.techfore.2014.09.007
Coccia M., Watts J. 2020. A theory of the evolution of technology: technological parasitism and the implications for innovation management. J Eng Technol Manage 55:101552. https://doi.org/10.1016/j.jengtecman.2019.11.003
David PA (1985) Clio and the economics of QWERTY. Am Econ Rev 76:332–337
David PA (1993) Path dependence and predictability in dynamic systems with local network externalities: a paradigm for historical economics. In: Foray D, Freeman C (eds) Technology and the wealth of nations: the dynamics of constructed advantage. Pinter Publishers, London, pp 208–231
Farrell CJ (1993) A theory of technological progress. Technol Forecast Soc Chang 44(2):161–178
Fisher JC, Pry RH (1971) A simple substitution model of technological change. Technol Forecast Soc Chang 3(2–3):75–88
Frankel M (1955) Obsolescence and technological change in a maturing economy. Am Econ Rev 45(3):296–319. Retrieved from http://www.jstor.org/stable/779
Freeman C (1974) The economics of industrial innovation. Penguin, Harmondsworth
Griliches Z (1957) Hybrid corn: an exploration in the economics of technological change. Econometrica 25:501–522
Hayami Y, Ruttan VW (1970) Factor prices and technical change in agricultural development: the United States and Japan, 1880–1960. J Polit Econ 78:1115–1141
Heidelberger M, Schiemann G (eds) (2009) The significance of the hypothetical in the natural sciences. Walter de Gruyter, Berlin/New York
Hicks J (1932/1963) The theory of wages. Macmillan, London
Hosler D (1994) The sounds and colors of power: the sacred metallurgical technology of Ancient West Mexico. MIT Press, Cambridge
Meeks J (1972) Concentration in the electric power industry: the impact of antitrust policy. Columbia Law Rev 72:64–130
Olmstead AL, Rhode P (1993) Induced innovation in American agriculture: a reconsideration. J Polit Econ 101(1):100–118. Stable URL: https://www.jstor.org/stable/2138675
Pistorius CWI, Utterback JM (1997) Multi-mode interaction among technologies. Res Policy 26(1):67–84
Rosenberg N (1976) On technological expectations. Econ J 86:523–535
Sahal D (1981) Patterns of technological innovation. Addison-Wesley, Reading
Schmookler J (1962) Determinants of industrial invention. In: Nelson RR (ed) The rate of direction of inventive activity: economic and social factors. Princeton University Press, Princeton
Schmookler J (1966) Invention and economic growth. Harvard University Press, Cambridge, MA
Schmookler J, Brownlee O (1962) Determinants of inventive activity. Am Econ Rev 52(2):165–176. Papers and Proceedings of the Seventy-Fourth Annual Meeting of the American Economic Association (May, 1962)
Utterback JM, Pistorius C, Yilmaz E (2020) The dynamics of competition and of the diffusion of innovations. MIT Sloan School of Management Working Paper-6054–20. https://hdl.handle.net/1721.1/124369
Download references
Author information
Authors and affiliations.
CNR – National Research Council of Italy, Torino, Italy
Mario Coccia
Yale University, New Haven, CT, USA
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Mario Coccia .
Editor information
Editors and affiliations.
Florida Atlantic University, Boca Raton, FL, USA
Ali Farazmand
Rights and permissions
Reprints and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this entry
Cite this entry.
Coccia, M. (2020). Comparative Hypotheses for Technology Analysis. In: Farazmand, A. (eds) Global Encyclopedia of Public Administration, Public Policy, and Governance. Springer, Cham. https://doi.org/10.1007/978-3-319-31816-5_3973-1
Download citation
DOI : https://doi.org/10.1007/978-3-319-31816-5_3973-1
Received : 26 March 2020
Accepted : 13 April 2020
Published : 19 June 2020
Publisher Name : Springer, Cham
Print ISBN : 978-3-319-31816-5
Online ISBN : 978-3-319-31816-5
eBook Packages : Springer Reference Economics and Finance Reference Module Humanities and Social Sciences Reference Module Business, Economics and Social Sciences
- Publish with us
Policies and ethics
- Find a journal
- Track your research
POLICY AND PRACTICE REVIEWS article
Research methods for education with technology: four concerns, examples, and recommendations.

- Department of Education Psychology and Higher Education, University of Nevada, Las Vegas, Las Vegas, NV, United States
The success of education with technology research is in part because the field draws upon theories and methods from multiple disciplines. However, drawing upon multiple disciplines has drawbacks because sometimes the methodological expertise of each discipline is not applied when researchers conduct studies outside of their research training. The focus here is on research using methods drawn largely from psychology, for example, evaluating the impact of different systems on how students perform. The methodological concerns discussed are: low power; not using multilevel modeling; dichotomization; and inaccurate reporting of the numeric statistics. Examples are drawn from a recent set of proceedings. Recommendations, which are applicable throughout the social sciences, are made for each of these.
Spending on EdTech is around 19 billion dollars per year ( Koba, 2015 ). Research on using computer technology within education began soon after microcomputers began appearing in universities (e.g., Suppes, 1966 ). Given the amount of accumulated wisdom in the field and the amount of investment, it is a concern that the current EdTech landscape has been likened to the Wild West ( Reingold, 2015 ), with schools buying systems without convincing evidence of their efficacy. There are many issues that researchers in the field can address to better serve schools ( Wright, 2018 ). One issue is what to call the field. I have been using the phrase Education with Technology (EwT) for research on education and educational outcomes when using technology. I use EdTech to refer to the technology companies that sell technology aimed specifically at the education market.
There is some excellent research examining the effectiveness of technology for learning. For example, decades of high-quality research by Anderson and colleagues (e.g., Anderson et al., 1985 ; Ritter et al., 2007 ) on the Cognitive Tutor has shown the successful application of cognitive science to education software (see https://www.carnegielearning.com/ ). Two important aspects of this success story are: (1) the applications developed alongside the theory (ACT-R) that Anderson had developed for cognition, and (2) the successful application to the classroom took decades of rigorous research. The focus of this paper is to improve the quality of existing research in order to allow more progress to occur.
Four concerns of research methods were chosen. These were picked both because examples were found where there are concerns and recommendations exist for improvement that can be easily accommodated. Many other topics, covering different design and analytic methods (e.g., robust methods, visualizations), could also have been included, but having four seems a good number so that each receives sufficient attention. The four concerns are:
1. Power analysis (the sample size can be too low to have an adequate likelihood of producing meaningful results);
2. Multilevel modeling (the units are not independent, which is assumed for traditional statistical tests, and this usually means that the p -values are lower than they should be);
3. Dichotomizing (continuous variables are turned into dichotomous variables at arbitrary points, like the median, thereby losing information);
4. Inaccurate statistical reporting (sometimes because of typos, sometimes because of reading the wrong output, the reported statistics are incorrect).
Choosing Examples
The field of EwT was chosen for three reasons. First, it offers valuable potential for education, though the impact has failed to live up to the potential/hype (see Cuban, 2001 ; Reingold, 2015 ). There are several possible reasons for this (e.g., Wright, 2018 ), one of which is that the methods and statistical procedures used in empirical studies leave room for improvement. Second, it is an area in which I have been working. Third, as a multidisciplinary field, different researchers bring different expertise. It may be that a research team does not have someone trained in psychology and social science research methods (e.g., Breakwell et al., 2020 ). As someone who is trained in these procedures, I hope to bring my skills to this field.
Some examples will be used both to show that these issues arise and to illustrate the problems. It is important to stress that in any field it is possible to find illustrations of different concerns. Papers from the 2017 Artificial Intelligence in Education (AIED) conference in Wuhan, China, were examined. This conference is a showcase for mostly academic researchers developing and evaluating new procedures and technologies. The papers are published in five categories: papers, posters, doctoral, industry, and tutorials. Only the papers and posters are examined here: the doctoral papers often sought advice on how to conduct the planned research; the industry papers often described a product or were a case study using a product; and the tutorials gave accounts of what their audiences would learn.
According to their website 1 , only 36 of the 121 papers submitted for oral presentations were accepted as oral presentations. Thirty-seven of these were accepted as posters (and 7 of 17 papers submitted for posters were accepted). Of the 138 total submissions, 80 were accepted as a paper or a poster (58% acceptance rate). There were 36 papers and 37 posters in the proceedings, so not all accepted posters appeared in the proceedings. The main difference between oral presentations and posters for the proceedings is that authors of oral presentations were allowed 12 pages of text for their papers and authors of posters were allowed only four pages of text. In many cases it was difficult to know what methods and statistical techniques were used, particularly for the posters, presumably because the authors had to make difficult choices of what to include because of the length restrictions.
Reflecting the multidisciplinarity of the field, the papers differed in their approaches. Some papers were primarily focused on statistical procedures to classify student responses and behaviors. Others were demonstrations of software. The focus here is on research that used methods common to what Cronbach (1957) called the experimental and correlational psychologies. Of the 63 full papers and posters, 43 (68%) involved collecting new data from participants/students not simply to show the software could be used. Some of these were described as “user studies” and some as “pilot studies.” It is important to stress that while examples will be shown to illustrate concerns, some aspects of these studies were good and overall the conference papers are high-quality. For example, those evaluating the effectiveness of an intervention tended to use pre- and post-intervention measures and compare those in the intervention condition with a control condition.
The methods—both the design of the study and the statistical procedures—were examined for concerns that a reviewer might raise. Four concerns are discussed here and recommendations are made. These were chosen both by how much they may affect the conclusions and how easily they can be addressed. While these comments are critical, the purpose of the paper is to be constructive for the field. Only a couple of examples are shown for each concern. These were picked because of how well they illustrate the concern. Before doing this, some background on hypothesis testing is worth providing. Some statistical knowledge about this procedure is assumed in this discussion. At the end of each section specific readings are recommended.
Crisis in Science and Hypothesis Testing
Educational with Technology research is not done in isolation. While the theme of this paper is to look at how EwT researchers deal with some issues, there is a crisis within the sciences more broadly that requires discussion. The crisis is due to the realization that a substantial proportion (perhaps most) of the published research does not replicate ( Ioannidis, 2005 ; Open Science Collaboration, 2015 ). This occurs even in the top scientific journals ( Camerer et al., 2018 ). This has led to many suggestions for changing how science is done (e.g., Munafò et al., 2017 ). For discussion see papers in Lilienfeld and Waldman (2017) and a recent report by Randall and Welser (2018) . Unfortunately using traditional methods, which have been shown to produce results that are less likely to be replicated, are ones that can make the researchers' CVs look better ( Smaldino and McElreath, 2016 ).
One aspect that many are critical of is the use and often mis-use of hypothesis testing. It is worth briefly describing what this is. In broad terms, a scientist has a set of data, assumes some model H for the data, and calculates the distribution of different characteristics for plausible samples assuming this model is true. Suppose some characteristics of the observed data are far away from the distribution of plausible samples. This would be very rare if your assumed model were correct. “It follows that if the hypothesis H be true, what we actually observed would be a miracle. We don't believe in miracles nowadays and therefore we do not believe in H being true” ( Neyman, 1952 , p. 43). There are some problems with this approach. If we only react when the data would require a miracle to have occurred if H is true, scientific findings would accumulate too slowly. Instead, for most research situations a threshold below miracle is needed to allow evidence to accumulate, but then it is necessary to accept that sometimes errors occur because of this lower threshold. Neyman ( 1952 , p. 55) called this “an error of the first kind ” ( emphasis in original). What is important here is that the possibility of error is not only recognized, but quantified.
Hypothesis testing is usually done by testing what is called the null hypothesis. This is usually a point hypothesis and that there is no effect of the independent variable, no difference between groups, or no association. It is often denoted as H 0 . As a single point, it can never be true. This creates a conceptual problem: the procedure assumes a hypothesis that is always false ( Cohen, 1994 ).
The conditional probability is usually called the p -value or sometimes just p . Calculating the p -value for different problems can be complex. Traditionally most researchers have accepted a 5% chance of making a Type 1 error when the null hypothesis is true. This is called the α (alpha) level and if the observed conditional probability is less than this, researchers have adopted the unfortunate tradition of saying it is “significant.” Unfortunate because finding p < 5% does not mean the effect is “significant” in the English sense of the word. If comparing the scores for two groups of students, finding a “significant” effect in a sample only provides information that the direction of the true effect in the population is likely the same as observed in the sample. Recently there has been a move to use different α levels. In some branches of physics it is set much lower (see Lyons, 2013 ) for discoveries because the cost of falsely announcing a discovery is so high that it is worth waiting to claim one only when the data would have had to arise by almost a “miracle” if the null hypothesis were true. Some social scientists think it is appropriate to have a lower threshold than this ( Benjamin et al., 2018 ), but others have pointed out problems with this proposal (e.g., Amrhein and Greenland, 2018 ; McShane et al., 2019 ). For current purposes 5% will be assumed because it remains the most used threshold.
There are other problems with the hypothesis testing approach and scientific practices in general. Alternatives have been put forward (e.g., more visualization, pre-registering research, Bayesian models), but each alternative has limitations and can be mis-used. The remainder of this paper will not address these broader issues.
Background Reading
The report by the Open Science Collaboration (2015) , while focusing on psychology research, discusses topics relevant to those applicable to the EwT studies considered. Cohen (1994) presents a good discussion of what null hypothesis significance testing is and is not.
Concern #1: Power Analysis and Small Samples
The hypothesis testing framework explicitly recognizes the possibility of errantly rejecting the null hypothesis. This has been the focus of much discussion because this can lead to publications that are accepted in journals, but do not replicate. Another problem is when research fails to detect an effect when the true effect is large enough to be of interest. This is a problem because this often limits further investigations. This is called a Type 2 error: “failure to reject H 0 when, in fact, it is incorrect, is called the error of the second kind” ( Neyman, 1942 , p. 303). As with Type 1 errors, the conditional probability of a Type 2 error is usually reported. Researchers specify the Minimum Effect that they design their study to Detect (MED). The conditional probability of a Type 2 error is usually reported as the probability of failing to find a significant effect conditional on this MED and is often denoted with the Greek letter β (beta). The statistical concept power is 1–β and convention is that it should usually be at least 80%. However, if it is relatively inexpensive to recruit participants or if your PhD/job prospects require that you detect an effect if it is as large as the MED, it would be wise to set your power higher, for example 95% (this is the default for the popular power package G * Power, Faul et al., 2007 , 2009 ).
Over the past 50 years several surveys of different literatures have shown that many studies have too few participants to be able to detect the effects of interest with a high likelihood (e.g., Sedlmeier and Gigerenzer, 1989 ). The problem of having too few participants exists in many fields. Button et al. (2013) , for example, found about 30% of the neuroscience studies they examined had power <11%. This means that these studies had only about a one-in-nine chance of observing a significant effect for an effect size of interest. It is important to re-enforce the fact that low power is a problem in many disciplines, not just EwT.
Conventional power analysis allows researchers to calculate a rough guide to how many participants to have in their study to give them a good chance of having meaningful results. Many journals and grant awarding bodies encourage (some require) power analysis to be reported. The specifics of power analysis are tightly associated with hypothesis testing, which is controversial as noted above, but the general notion that the planned sample size should be sufficient to have a high likelihood of yielding meaningful information is undisputed. If researchers stop using hypothesis testing, they will still need something like power analysis in order to plan their studies and to determine a rule for when to stop collecting data.
Tables (e.g., Cohen, 1992 ) and computer packages (e.g., Faul et al., 2007 , 2009 ) are available to estimate the sample size needed to have adequate power for many common designs. Simulation methods can be used for more complex designs not covered by the tables and packages (e.g., Browne et al., 2009 ; Green and MacLeod, 2016 ).
Deciding the minimum effect size for your study to detect (MED) is difficult. For many education examples a small improvement in student performance, if applied throughout their schooling, can have great consequences. For example, Chetty et al. (2011) estimated that a shift upwards of 1 percentile in test scores during kindergarten is associated with approximately an extra $130 per annum income when the student is 25–27 years old. When multiplied across a lifetime this becomes a substantial amount. Researchers would like to detect the most miniscule of effects, but that would require enormous samples. The cost would not be justified in most situations. It is worth contrasting this message with the so-called “two sigma problem.” Bloom (1984) discussed how good one-on-one tutoring could improve student performance a large amount: two sigma (two standard deviations) or from the 50th percentile to the 98th percentile. He urged researchers to look for interventions or sets of interventions that could produce shifts of this magnitude. Many in the EwT arena talk about this as a goal, but for product development to progress research must be able to identify much smaller shifts.
The choice of MED is sometimes influenced by the observed effects from similar studies. If you expect the effect to be X, and use this in your power calculations, then if your power is 80% this means that you have about a 4 in 5 chance of detecting the effect if your estimate of the expected effect is fairly accurate. However, if you are confident that your true effect size is X, then there is no reason for the study. It is usually better to describe the MED in relation to what you want to be able to detect rather than in relation to the expected effect.
To allow shared understanding when people discuss effect sizes, many people adopt Cohen's (1992) descriptions of small, medium, and large effects. While people have argued against using these without considering the research context ( Lipsey et al., 2012 ), given their widespread use they allow people to converse about effect sizes across designs and areas.
Two Examples
Two examples were chosen to show the importance of considering how many participants are likely to complete the study. The studies show the importance of considering what the minimum effect size to detect (MED) should be. Overall, across all 43 studies, the sample sizes ranged from <10 to 100.
Arroyo et al. (2017) compared collaboration and no collaboration groups. They collected pre and post-intervention scores and the plan was to compare some measure of improvement between the groups. Originally there were 52 students in the collaboration group and 57 in the no collaboration group. If they were using G * Power ( Faul et al., 2007 , 2009 ) and wanted a significance level of 5% and power of 80%, it appears the MED that they were trying to detect was d = 0.54sd. This MED is approximately the value Cohen describes as a medium effect. This value might be reasonable depending on their goals. Only 47 students completed the post-test. Assuming 24 and 23 of these students were in the two groups, respectively, the power is now only 44%. They were more likely to fail to detect an effect of this size than to detect one.
Another example where the sample size decreased was Al-Shanfari's et al. (2017) study of self-regulated learning. They compared three groups that varied depending on the visualizations used within the software (their Table 1). One hundred and ten students were asked to participate. This is approximately the sample size G * Power suggests for a one-way Anova with α = 5%, power of 80%, and a MED of f = 0.3, which is between Cohen's medium and large effects. The problem is some students did not agree to participate and others did not complete the tasks. This left few students: “9 students remained in the baseline group, 9 students in the combined group and 7 in the expandable model group” (p. 20). Assuming the same α and MED, the power is now about 22%. Even if the authors had found a significant effect, with power this low, the likelihood is fairly high that the direction of the effect could be wrong ( Gelman and Carlin, 2014 ).
Were these MEDs reasonable? The choice will vary by research project and this choice can be difficult. As noted above, in educational research, any manipulation that raises student outcomes, even a minute amount, if applied over multiple years of school, can produce large outcomes. Further, a lot of research compares an existing system to one with some slight adaptation so the expected effect is likely to be small. If the adaptation is shown to have even a slight advantage it may be worth implementing. If Arroyo et al. (2017) and Al-Shanfari et al. (2017) planned to design their studies to detect what Cohen (1992) calls small effects ( d = 0.2 and f = 0.1), the suggested samples sizes would have been n = 788 and n = 969. To yield 80% power to detect a 1 percentile shift, which Chetty et al. (2011) noted could be of great value, would require more than 10,000 students in each group.
Recommendations
1a. Report how you choose your sample size (as well as other characteristics of your sample). This often means reporting a power analysis. Try to have at least the number of participants suggested by the power analysis and justify the MED you used. The expected drop out rate should be factored into these calculations.
1b. If it is not feasible to get the suggested number of participants,
- Do not just do the study anyway. The power analysis shows that there is a low likelihood to find meaningful results so your time and your participants' time could be better spent. And do not just change the MED to fit your power analysis.
- Use more reliable measurements or a more powerful design (e.g., using covariates can increase power, but be careful, see for example, Meehl, 1970 ; Wright, 2019 ).
- Combine your efforts with other researchers. This is one of Munafò et al.'s (2017) recommendations and they give the example of The Many Lab ( https://osf.io/89vqh/ ). In some areas (e.g., high-energy particle physics) there are often dozens of authors on a paper. The “authors” are often differentiated by listing a few as co-speakers for the paper, and/or having some listed as “contributors” rather than “authors.”
- Change your research question. Often this means focusing your attention on one aspect of a broad topic.
- Apply for a grant that allows a large study to be conducted.
Caveat: Power analyses are not always appropriate. Power analysis is used to suggest a sample size. If you are just trying to show that your software can be used, then you do not need a large sample.
Cohen (1992) provides a brief primer for doing power analysis for many common research designs. Baguley (1994) and Lenth (2001) provide more critical perspectives of how power analysis is used.
Concern #2. Multilevel Modeling
Two common situations where multilevel modeling is used in education research are when the students are nested within classrooms and when each student has data for several measurements. For the first situation, the data for the students are said to be nested within the classrooms and for the second the measurements nested within the students. The problem for traditional statistical methods is that the data within the same higher level unit tend to be more similar with each other than with those in other units. The data are not independent: an assumption of most traditional statistical procedures. Educational statisticians and educational datasets have been instrumental in the development of ways to analyze data in these situations (e.g., Aitken et al., 1981 ; Aitkin and Longford, 1986 ; Goldstein, 2011 ). The approach is also popular in other fields, for example within ecology (e.g., Bolker et al., 2009 ), geography (e.g., Jones, 1991 ), medicine (e.g., Goldstein et al., 2002 ), psychology (e.g., Wright, 1998 ), and elsewhere. The statistical models have several names that can convey subtle differences (e.g., mixed models, hierarchical models, random coefficient models). Here the phrase “multilevel models” is used.
Suppose you are interested in predicting reading scores for a 1,000 students in a school district equally divided among 10 schools from hours spent on educational reading software. Both reading scores and hours spent likely vary among schools. If you ran the traditional regression:
It is assumed that the e i are independent of each other, but they are not. There are a few approaches to this; the multilevel approach assumes each of the 10 schools has a different intercept centered around a grand intercept, β 0 in Equation (1). The method assumes these are normally distributed and estimates the mean and standard deviation of this distribution. Letting the schools be indexed by j , the multilevel equation is:
where u j denotes the variation around the intercept. Most of the main statistical packages have multilevel procedures.
The R statistics environment ( R Core Team, 2019 ) will be used for this, and subsequent, examples 2 . It was chosen because of functionality (there are over ten thousand packages written for R) and because it is free, and therefore available to all readers. It can be downloaded from: https://cran.r-project.org/ . Here the package lme4 ( Bates et al., 2015 ) will be used. To fit the model in Equation (2) with a multilevel linear model you enter:
lmer(reading ~ hours + (1|school))
The two examples were picked to illustrate the two main ways that education data are often multilevel. The first is when the students are nested within classrooms and this is one of the first applications of multilevel modeling to education data (e.g., Aitkin and Longford, 1986 ). The second is where the students have several measurements. The measurements can be conceptualized as nested within the individual. These are often called repeated measures or longitudinal designs.
The textbook education example for multilevel modeling is where students are nested within a class. Li et al. (2017) used this design with 293 students nested within 18 classrooms. They compared student performance on inquiry and estimation skills using a linear regression. Inference from this statistic assumes that the data are independent from each other. It may be that the students in the different classrooms behave differently on these skills and that the teachers in these classrooms teach these skills differently. In fact, these are both highly likely. Not taking into account this variation is more likely to produce significant results than if appropriate analyses were done. Therefore, readers should be cautious with any reported p -values and the reported precision of any estimates.
Another common application of multilevel modeling is where each student provides multiple data points, as with Price et al. (2017) study of why students ask for a hint and how they use hints. Their data set had 68 students requesting 642 hints. Hints are nested within students. Students were also nested within classes and hints within assignments (and hints were sometimes clustered together), but the focus here is just hints being nested within students. The authors state that “the number of hints requested by student varied widely” (p. 316) so they were aware that there was student-level variation in hint frequency. There likely was also variation among students for why they requested hints and how they used the hints. One interest was whether the student did what the hint suggested: a binary variable. A generalized linear multilevel model could be used to predict which students and in which situations hints are likely to be followed. Instead Price et al. rely mostly on descriptive statistics plus a couple of inferential statistics using hints as the unit of study, thereby ignoring the non-independence of their data. Thus, their standard errors and p -values should not be trusted. For example, they examined whether how much time was spent looking at a hint predicted whether the hint was followed without considering that this will likely vary by student. Following a hint is a binary variable, and often a logistic regression is used for this. The lme4 package has a function for generalized linear multilevel regressions called glmer . Here is a model that they could have considered.
glmer(followHint ~ time + (1|student), family = "binomial")
While treating time as either a linear predictor of the probability of following a hint, or linear with the logit of the probability, is probably unwise, a curved relationship (e.g., a b-spline) could be estimated and plotted within the multilevel modeling framework. In R there is a function, bs, for b-splines:
glmer(follow ~ bs(time) + (1|student), family = "binomial")
2a. When the data are clustered in some way so that information about one item in a cluster provides information about others in the cluster, the data are not independent. This is an assumption of traditional statistical tests. The resulting p -values will usually be too low, but sometimes they will be too high, and sometimes the effects will be in the opposite direction. Alternatives should be considered. If the non-independence is ignored there should be justification and readers should be cautious about the uncertainty estimates (including p -values) of the results.
2b. There are alternatives to multilevel modeling. Some latent variable (including item response theory [IRT]) and Bayesian approaches can take into account individual variation and are sometimes nearly equivalent. In some disciplines it is common to estimate separate values for each school or student, what is sometimes called the fixed effect approach. There are arguments against this approach (e.g., Bell and Jones, 2015 ), but sometimes estimation problems with multilevel models mean the fixed effect is preferred ( Wright, 2017 ).
2c. When the data have a multilevel structure, multilevel modeling (or some other way to take into account the non-independence of the data) should be used. There are many resources available at http://www.bristol.ac.uk/cmm/learning/ to learn more about these procedures. Several multilevel packages are reviewed at http://www.bristol.ac.uk/cmm/learning/mmsoftware/ . Many free packages are available in R and these are discussed at: http://bbolker.github.io/mixedmodels-misc/MixedModels.html .
Goldstein (2011) provides detailed mathematical coverage of multilevel modeling. Hox (2010) provides a detailed textbook that is less mathematical. Field and Wright (2011) is an applied introduction.
Concern #3. Dichotomizing
Numerous authors have criticized researchers for splitting continuous measures into a small number of categories at arbitrary cut-points (e.g., Cohen, 1983 ; MacCallum et al., 2002 ). Sometimes the cut-scores are chosen at particular points for good reasons (e.g., the boiling and freezing points for water, the passing score on a teenager's driving test to predict parent anxiety), but even in these situations some information is lost and these particular breakpoints could be accounted for by allowing discontinuities in the models used for the data.
Consider the following example. Figure 1A shows the proportions of positive ratings for rigor and collaboration for New York City schools in 2014–2015 3 . The two variables are not dichotomized and there is a clear positive relationship. Other aspects of the data are also apparent, like the increased variance for lower values (proportions tend to have larger variance near 50% than at the extremes) and also the non-linearity related to 1.0 being the highest possible proportion. Non-linearity is important to examine. Figures 1B–D shows that information is lost when dichotomizing either variable. In Figure 1B the x-variable (rigorous) has been dichotomized by splitting the variable at the median, a procedure called a median split. The median is 0.86. Therefore, this procedure treats 0.70 and 0.85 as the same, and 0.87 and 0.99 as the same, but assumes there is some leap in rigor between 0.85 and 0.87. In Figure 1C the y-variable, collaboration, has been dichotomized. Here information about how collaborative a school is—beyond just whether they are in the top 50% of schools or not—is lost. In Figure 1D both variables have been dichotomized. The researcher might conduct a 2 × 2 χ 2 , but would not be able to detect any additional interesting patterns in the data.

Figure 1 . Data from New York City schools on the relationship between collaborative and rigorous ratings. (A) Shows the original variables. (B–D) Dichotomize the variables thereby presenting less information. A slight random “jitter” has been added to the values of dichotomized variables so that it can be seen when multiple schools have similar values.
The examples were chosen to illustrate two issues with dichotomization. The first was chosen because it uses a common, but much criticized, procedure called a median split. The choice of the example was also based on the authors providing enough data so that samples could be created that are consistent with the dichotomized data but lead to different conclusions if not dichotomized. The second example involves the authors using a complex method to dichotomize the data. This was chosen to stress that using a complex procedure does not prevent the loss of information.
Perez et al. (2017) allocated students either to a guided or to an unguided learning condition, and then focused on those 74 students who performed less well on a pre-test. They transformed the post-test score using a median split (they do not say how values at the median are classified, but here it is assumed the “high” group is at or above the median). Table 1 shows the results. Using a 2 × 2 χ 2 with Yates' correction the result is χ ( 1 ) 2 = 0.21, p = 0.65, with an odds ratio of 1.37 (the null is 1.00) with a 95% confidence interval from 0.50 to 3.81 (found using the odds.ratio function in the questionr package, Barnier et al., 2017 ). While the condition variable is a truly dichotomous variable—participants were either in the guided condition or not—the post-test scores vary. Dichotomizing the variable loses information about how much above or below the median the scores were.

Table 1 . The cross-tabulation table for ( Perez et al., 2017 ) data.
It is likely that Perez et al. (2017) were interested in whether their manipulation affected post-test scores. If they had analyzed their data taking into account information lost by dichotomizing, they might have detected a statistically significant difference. Suppose their post-scores were based on responses to 10 items. The data in Sample 1 in Table 2 are consistent with the dichotomized values in Table 1 . Perez et al. might have conducted a Wilcoxon rank sum test, calculated here using the defaults of R's function wilcox.test . A t -test leads to similar results, but readers might question the distribution assumptions of the t -test for these data. The result for Sample 1 is W = 472.5, a p -value of 0.02, with the guided condition performing better. The researchers could have concluded an advantage for this approach.

Table 2 . Possible datasets for the data in Table 1 .
However, Sample 2 of Table 2 is also consisted with the dichotomized values. It has W = 893.5, p = 0.02, but this finding is in the opposite direction with the guided condition doing worse. Perez et al.'s (2017) data might be like Sample 1, Sample 2, or neither of these.
The study by Li et al. (2017 , their Table 2) was mentioned earlier because multilevel modeling could have been used, but their use of dichtomization is also noteworthy. They recorded the number of inquiry skills and explanation skills each student used, and conducted some preliminary statistics. They dichotomize both variables (like Figure 1D ). Rather than using a median split on the total scores, they ran a K = 2 means cluster analysis on the individual items. The authors label the clusters high and low. If evidence were presented that people really were in two relatively homogeneous groups (using for example, taxometric methods, Waller and Meehl, 1998 ) then this could have been appropriate but if the constructs are dimensions information is lost. They then test the association that these dichotomized variables are associated and found the Pearson χ ( 1 ) 2 = 6.18, p = 0.01. Interestingly, they also calculated Pearson's correlation using the continuous measures ( r = 0.53, p < 0.001). It is unclear why both were done and, in relation to significance testing, it is inappropriate to test the same hypothesis multiple times even if one is inappropriate.
There are reasons to dichotomize. If the continuous variable results in a dichotomy, and that dichotomy is of interest, then dichotomizing can be useful. Sometimes it is useful to include a dummy variable for whether a person partakes in some behavior (e.g., having a computer at home; being an illegal drug user) and the amount of that behavior (e.g., hours at home using the computer; frequency of drug use). The concern here is when dichotomization (or splitting into more than two categories) is done without any substantive reason and where the cut-off points are not based on substantive reasons. Sometimes continuous variables are split into categories so that particular plots (e.g., barplots) and types of analyses (e.g., Anova, χ 2 tests) can be used as opposed to scatter plots and regression.
3a. If you believe a continuous variable or set of continuous variables may be based on a small number of categorical constructs, use appropriate methods (e.g., taxometric methods, Waller and Meehl, 1998 ) to justify this.
3b. Consider non-linear and dis-continuous models. Dummy variables can be included, along with quantitative variables, in regression models if you believe there are certain discontinuities in relationships.
3c. Do not dichotomize a variable just to allow you to use a statistical or graphical procedure if there are appropriate and available procedures for the non-dichotomized variables.
( MacCallum et al., 2002 ) provides a detailed and readable discussion about why dichotomization should usually be avoided.
Concern #4. Errors in Numbers
Humans, including myself, make typing mistakes.
There are several reasons why people distrust scientific results. The easiest of these to address is errors in the numbers reported in tables and statistical reports. These types of errors will always be part of any literature, but it is important to lessen their likelihoods. Some examples were chosen to show different types of errors.
Some Examples
Pezzullo et al. ( 2017 , p. 306) report the following F statistics:
F (1, 115) = 2.4579, p = 0.0375 “significant main effect”
F (1, 115) = 2.9512, p = 0.0154 “significant interaction”
The p -values associated with these F statistics should be 0.12 and 0.09, respectively. The authors have turned non-significant findings into significant ones. There is no reason to think that this was a deliberate fabrication. If the authors had wanted to create significant effects where there was none, and they wanted to conceal this act, they could have changed the F -values too.
Some errors can be found with software like the freeware statcheck ( Nuijten et al., 2016 ). It reads statistical text and tries to determine if the statistic and p -value match. If in R (with the statcheck package loaded) you write:
statcheck("F(1,115) = 2.4579, p = .0375")
it tells you that there may be some errors in the expression. The software has been created to allow entire text to be analyzed, parsing out the statistical material. Nuijten and colleagues used this to analyze data from several American Psychological Association (APA) journals. They found that about 10% of p -values reported were incorrect. The package does not catch all errors so should not be the only thing relied upon to check a manuscript before submission (an analogy would be just using a spellchecker rather than proofreading).
Another example is from Talandron et al. ( 2017 , p. 377). They were interested in the incubation effect where waiting to solve a problem after failure can help to produce the correct response. One of their key findings was “the average number of attempts prior to post-incubation of all IE-True (M = 32, SD = 21) was significantly lower than those of IE-False (M = 46, SD = 22) [ t (169) = 1.97, two-tailed p < 0.01].” The true p -value for t (169) = 1.97 is 0.05.
The errors by Pezzullo et al. and Talandron et al. were relatively easy to identify. Other errors can be more difficult to notice. Sjödén et al. ( 2017 , p. 353) analyzed data of 163 students playing 3,983 games. They compared the number of games played by each student with the student's average goodness rating and found “Pearson r = 0.146; p = 0.000.” The p associated with r = 0.146 with n = 163 is, two-tailed, 0.06. The likely source of the error is that the wrong n has been used either when looking up the p -value manually or these student-level variables were repeated for each game the student played in the data file and the authors took the numbers from the statistics package without noticing this problem.
It is important to check the degrees of freedom carefully, because errant degrees of freedom may mean the wrong statistic is being reported. For example, Kumar ( 2017 , p. 531) compared student performance before and after some changes were made to the software that he was examining. He reports no significant main effect between these two groups. He then repeated the analyses including a covariate: number of puzzles solved during the task. He reports that the main effect is now significant: F (2,169) = 3.19, p = 0.044. The 2 in the numerator of the degrees of freedom is odd. There are only two groups so there should only be 1 degree of freedom for the numerator if this is a test of the difference between the model with the covariate and the model with the covariate plus the single grouping variable that distinguishes the two groups. If it is a typo and it is 1 then the F and/or the p is wrong. From the description it appears that the covariate also has only one degree of freedom. Because some statistics software produces the F value for the entire model as well as its components, it could be that Kumar took the statistic from the wrong part of the output. He argues that the covariate should have been associated with the outcome, so it would not be surprising that the covariate plus the group difference were statistically significant.
4a. While packages like statcheck ( Nuijten et al., 2016 ) can catch some errors, they will not catch all errors. As the software evolves, more (but not all) errors will be caught. This might have the negative affect of people relying on it too much (like not learning to spell because of the ubiquity of spellcheckers). Given that only some errors will be caught it is important not to treat this as if it is checking all numeric output. There will always be the chance of some typographical errors, but it is worth using modern technology to catch some errors.
4b. Procedures exist to include the statistical code in your word processing document that reads the data and creates the numeric output (and plots) directly. An example is the package knitr ( Xie, 2015 ). It allows you to write your paper in LaTeX and have chunks of R (and many other statistical packages), typing
names(knitr::knit_engines$get())
in R currently (Nov. 20, 2019) shows 41 languages, including STATA, SAS, Java Script, and Python) embedded within it. An author could write “The p -value was \Sexpr{t.test(DV~IV)$p.value}” in LaTeX and the p -value would appear in the document. This has the additional advantage that if an error in the data file is discovered and fixed, then the tables, plots, and any statistics embedded in the text can be automatically corrected.
4c. While the responsibility for checking numbers and words is primarily the authors, the reviewing process for conferences and journals could identify some of these errors and allow the authors to correct them. Some journals already do this. For example the Association of Psychological Science (APS) uses statcheck both before manuscripts are sent for review and it is required that authors submit a statcheck report with their final submission ( https://www.psychologicalscience.org/publications/psychological_science/ps-submissions#STATCHK ). It may be worthwhile to have statistical and methods reviews of submissions as is done in some medical journals. Some of the issues are discussed in Altman (1998) . If there are not enough statistics reviewers, other reviewers could be given guidelines for when to direct a submission to a statistics/methods reviewer. Example guidelines are in Greenwood and Freeman (2015) .
The statcheck webpage ( https://mbnuijten.com/statcheck/ ) has links to sources showing show to use it. The web page for knitr ( https://yihui.name/knitr/ ) will also provide more up-to-date information about at least that package than print sources. For advice to journal and conference referees and editors, see Greenwood and Freeman (2015) .
The crisis in behavioral science has led to several guidelines for how to avoid some of the pitfalls (e.g., Munafò et al., 2017 ). These include teaching more fundamentals and ethical issues in statistics and methods courses, pre-registering research design/analytic methods, using alternatives to hypothesis testing, and more transparent methods for disseminating research findings. These are issues within the current crisis in science. Stark and Saltelli (2018) discuss an under-lying cause of why bad science abounds: Cargo Cult Statistics. This is a phrase taken from Feynman's (1974) famous commencement address “Cargo Cult Science,” which itself is taken from Worsley (1957) . Stark and Saltelli define the statistical variety as “the ritualistic miming of statistics rather than conscientious practice” ( Stark and Saltelli, 2018 , p. 40). They describe how this miming is often the most effective way to get papers published (have it superficially look like other published papers) and having many publications is necessary for career development in modern academia. It is important to focus on both the broad issues like how research organizations reward output and on the specific issues that have created cargo cult statistics. The focus here is on how to address the more specific issues.
The area examined was the field of Education with Technology (EwT) and studies that might fit content-wise within applied psychology. EwT was chosen because of its importance for society. Its inter-disciplinarity means many of those conducting research had their formal research training outside that of those disciplines that tend to conducted studies on human participants. The hope is that this paper provides some helpful guidance.
Four issues were chosen in part because they can be addressed by researchers relatively easily: power analysis, multilevel modeling, dichotomization, and errors when reporting numeric statistics. Other issues could have been included (e.g., using better visualizations, using more robust methods), and with all of these issues, studies from many fields also show these (and other) concerns.
A small number of underlying themes relate both to the issues raised in this paper for EwT and to the crisis in science more generally.
1. Don't get excited by a p -value.
2. Don't think that because a paper is published that it is replicable and certainly not that it is the end of the story. The evidence reported in papers contributes to the story.
3. Empirical science, done well, is difficult and time-consuming. Time taken planning research is usually well spent.
4. The goals of science are different than the goals of many scientists and are not perfectly aligned with the structures put in place to reward scientists.
Author Contributions
The author confirms being the sole contributor of this work and has approved it for publication.
DW is the Dunn Family Foundation Endowed Chair of Educational Assessment, and as such receives part of his salary from the foundation.
Conflict of Interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
1. ^ http://www.springer.com/cda/content/document/cda_downloaddocument/9783319614243-p1.pdf?SGWID=0-0-45-1609692-p180928554 (accessed May 5, 2018).
2. ^ Power analyses (Concern #1) can also be conducted in R. There are function in the base R package including power.t.test and specialized packages for more involved designs including PoweR ( Lafaye de Micheaux and Tran, 2016 ) and pwr ( Champely, 2018 ).
3. ^ From https://data.cityofnewyork.us/Education/2014-2015-School-Quality-Reports-Results-For-High-/vrfr-9k4d .
Aitken, M., Anderson, D. A., and Hinde, J. P. (1981). Statistical modelling of data on teaching styles (with discussion). J. R. Stat. Soc. Ser. A 144, 419–461. doi: 10.2307/2981826
CrossRef Full Text | Google Scholar
Aitkin, M., and Longford, N. (1986). Statistical modelling issues in school effectiveness studies. J. R. Stat. Soc. Ser. A 149, 1–43. doi: 10.2307/2981882
Al-Shanfari, L., Epp, C. D., and Baber, C. (2017). “Evaluating the effect of uncertainty visualization in open learner models on students' metacognitive skills,” in Artificial Intelligence in Education , eds E. André, R. Baker, X. Hu, M. M. T. Rodrigo, and B. du Boulay (Gewerbestrasse: Springer), 15–27. doi: 10.1007/978-3-319-61425-0_2
Altman, D. G. (1998). Statistical reviewing for medical journals. Stat. Med. 17, 2661–2674. doi: 10.1002/(SICI)1097-0258(19981215)17:23<2661::AID-SIM33>3.0.CO;2-B
PubMed Abstract | CrossRef Full Text | Google Scholar
Amrhein, V., and Greenland, S. (2018). Remove, rather than redefine, statistical significance. Nat. Hum. Behav. 2:4. doi: 10.1038/s41562-017-0224-0
Anderson, J. R., Boyle, C. F., and Reiser, B. J. (1985). Intelligent tutoring systems. Science 228, 456–462. doi: 10.1126/science.228.4698.456
Arroyo, I., Wixon, N., Allessio, D., Woolf, B., Muldner, K., and Burleson, W. (2017). “Collaboration improves student interest in online tutoring,” in Artificial Intelligence in Education , eds E. André, R. Baker, X. Hu, M. M. T. Rodrigo, and B. du Boulay (Gewerbestrasse: Springer), 28–39. doi: 10.1007/978-3-319-61425-0_3
Baguley, T. (1994). Understanding statistical power in the context of applied research. Appl. Ergon. 35, 73–80. doi: 10.1016/j.apergo.2004.01.002
Barnier, J., François, B., and Larmarange, J. (2017). Questionr: Functions to Make Surveys Processing Easier. R Package Version 0.6.2 . Available online at: https://CRAN.R-project.org/package=questionr
Google Scholar
Bates, D., Mäechler, M., Bolker, B., and Walker, S. (2015). Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48. doi: 10.18637/jss.v067.i01
Bell, A. J. D., and Jones, K. (2015). Explaining fixed effects: random effects modelling of time-series, cross-sectional and panel data. Polit. Sci. Res. Method. 3, 133–153. doi: 10.1017/psrm.2014.7
Benjamin, D. J., Berger, J. O., Johannesson, M., Nosek, B. A., Wagenmakers, E. J., Berk, R., et al. (2018). Redefine statistical significance. Nat. Hum. Behav. 2, 6–10. doi: 10.1038/s41562-017-0189-z
Bloom, B. S. (1984). The 2 sigma problem: the search for methods of group instruction as effective as one-to-one tutoring. Edu. Res. 13, 4–16. doi: 10.3102/0013189X013006004
Bolker, B. M., Brooks, M. E., Clark, C. J., Geange, S. W., Poulsen, J. R., Stevens, M. H. H., et al. (2009). Generalized linear mixed models: a practical guide for ecology and evolution. Trends Ecol. Evol. 24, 127–135. doi: 10.1016/j.tree.2008.10.008
Breakwell, G. M., Wright, D. B., and Barnett, J. (2020). Research Methods in Psychology. 5th Edn . London: Sage Publications.
Browne, W. J., Golalizadeh Lahi, M., and Parker, R. M. A. (2009). A Guide to Sample Size Calculations for Random Effect Models via Simulation and the MLPowSim Software Package . University of Bristol.
Button, K. S., Ioannidis, J. P. A., Mokrysz, C., Nosek, B. A., Flint, J., Robinson, E. S. J., et al. (2013). Power failure: why small sample size undermines the reliability of neuroscience. Nat. Rev. Neurosci. 14, 365–376. doi: 10.1038/nrn3475
Camerer, C. F., Dreber, A., Holzmeister, F., Ho, T-H., Huber, J., and Johannesson, M (2018). Evaluating the replicability of social science experiments in Nature and Science between 2010 and 2015. Nat. Hum. Behav. 2, 637–644. doi: 10.1038/s41562-018-0399-z
Champely, S. (2018). Pwr: Basic Functions for Power Analysis. R Package Version 1.2-2 . Available online at: https://CRAN.R-project.org/package=pwr
Chetty, R., Friedman, J., Hilger, N., Saez, E., Schanzenbach, D., and Yagan, D. (2011). How does your kindergarten classroom affect your earnings? Evidence from Project STAR. Q. J. Econ. 126, 1593–1660. doi: 10.1093/qje/qjr041
Cohen, J. (1983). The cost of dichotomization. Appl. Psychol. Meas. 7, 249–253. doi: 10.1177/014662168300700301
Cohen, J. (1992). A power primer. Psychol. Bull. 112, 155–159. doi: 10.1037/0033-2909.112.1.155
Cohen, J. (1994). The earth is round ( p < 0.05). Am. Psychol. 49, 997–1003. doi: 10.1037/0003-066X.49.12.997
Cronbach, L. J. (1957). The two disciplines of scientific psychology. Am. Psychol. 12, 671–684. doi: 10.1037/h0043943
Cuban, L. (2001). Oversold and Underused: Computers in the Classroom . Cambridge, MA: Harvard University Press.
Faul, F., Erdfelder, E., Buchner, A., and Lang, A.-G. (2009). Statistical power analyses using G * Power 3.1: tests for correlation and regression analyses. Behav. Res. Methods , 41, 1149–1160. doi: 10.3758/BRM.41.4.1149
Faul, F., Erdfelder, E., Lang, A.-G., and Buchner, A. (2007). G * Power 3: a flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav. Res. Methods , 39, 175–191. doi: 10.3758/BF03193146
Feynman, R. P. (1974). Cargo cult science. Eng. Sci. 37, 10–13.
Field, A. P., and Wright, D. B. (2011). A primer on using multilevel models in clinical and experimental psychopathology research. J. Exp. Psychopathol. 2, 271–293. doi: 10.5127/jep.013711
Gelman, A., and Carlin, J. (2014). Beyond power calculations: assessing type S (sign) and type M (magnitude) errors. Perspect. Psychol. Sci. 9, 641–651. doi: 10.1177/1745691614551642
Goldstein, H. (2011). Multilevel Statistical Models. 4th Edn . Chichester: Wiley. doi: 10.1002/9780470973394
Goldstein, H., Browne, W. J., and Rasbash, J. (2002). Multilevel modelling of medical data. Stat. Med. 21, 3291–3315. doi: 10.1002/sim.1264
Green, P., and MacLeod, C. J. (2016). simr: An R package for power analysis of generalized linear mixed models by simulation. Methods Ecol. Evol. 7, 493–498. doi: 10.1111/2041-210X.12504
Greenwood, D. C., and Freeman, J. V. (2015). How to spot a statistical problem: advice for a non-statistical reviewer. BMC Med. 13:270. doi: 10.1186/s12916-015-0510-5
Hox, J. J. (2010). Multilevel Analysis. Techniques and Applications. 2nd Edn . New York, NY: Routledge. doi: 10.4324/9780203852279
Ioannidis, J. P. A. (2005). Why most published research findings are false. PLoS Med. 2:e124. doi: 10.1371/journal.pmed.0020124
Jones, K. (1991). Multi-Level Models for Geographical Research . Norwich, UK: Environmental Publications.
Koba, M. (2015). Education Tech Funding Soars–But Is It Working in the Classroom? Fortune . Available online at: http://fortune.com/2015/04/28/education-tech-funding-soars-but-is-it-working-in-the-classroom/
Kumar, A. N. (2017). “The effect of providing motivational support in Parsons puzzle tutors,” in Artificial Intelligence in Education , eds E. André, R. Baker, X. Hu, M. M. T. Rodrigo, and B. du Boulay (Gewerbestrasse: Springer), 528–531. doi: 10.1007/978-3-319-61425-0_56
Lafaye de Micheaux, P., and Tran, V. A. (2016). PoweR: a reproducible research tool to ease Monte Carlo power simulation studies for goodness-of-fit tests in R. J. Stat. Softw. 69, 1–42. doi: 10.18637/jss.v069.i03
Lenth, R. V. (2001). Some practical guidelines for effctive sample size determination. Am. Stat. 55, 187–193. doi: 10.1198/000313001317098149
Li, H., Gobert, J., and Dickler, R. (2017). “Dusting off the messy middle: Assessing students' inquiry skills through doing and writing,” in Artificial Intelligence in Education , eds E. André, R. Baker, X. Hu, M. M. T. Rodrigo, and B. du Boulay (Gewerbestrasse: Springer), 175–187. doi: 10.1007/978-3-319-61425-0_15
Lilienfeld, S. O., and Waldman, I. D. (Eds.). (2017). Psychological Science Under Scrutiny: Recent Challenges and Proposed Solutions . New York, NY: Wiley. doi: 10.1002/9781119095910
Lipsey, M., Puzio, K., Yun, C., Hebert, M. A., Roberts, M., Anthony, K. S., et al. (2012). Translating the Statistical Representation of the Effects of Education Interventions Into More Readily Interpretable Forms. National Center for Education Statistics (NCSER 20133000) . Washington, DC: IES. Available online at: https://ies.ed.gov/ncser/pubs/20133000/pdf/20133000.pdf
Lyons, L. (2013). Discovering the Significance of 5σ . Available online at: https://arxiv.org/pdf/1310.1284
MacCallum, R. C., Zhang, S., Preacher, K. J., and Rucker, D. D. (2002). On the practice of dichotomization of quantitative variables. Psychol. Methods 7, 19–40. doi: 10.1037//1082-989X.7.1.19
McShane, B. B., Gal, D., Gelman, A., Robert, C., and Tackett, J. L. (2019). Abandon statistical significance. Am. Stat. 73, 235–245. doi: 10.1080/00031305.2018.1527253
Meehl, P. E. (1970). “Nuisance variables and the ex post facto design,” in Minnesota Studies in the Philosophy of Science: Vol IV. ANALYSIS of Theories and Methods of Physics and Psychology , eds M. Radner and S. Winokur (Minneapolis, MN: University of Minnesota Press), 373–402.
Munafò, M. R., Nosek, B. A., Bishop, D. V. M., Button, K. S., Chambers, C. D., Percie du Sert, N., et al. (2017). A manifesto for reproducible science. Nat. Hum. Behav. 1:0021. doi: 10.1038/s41562-016-0021
Neyman, J. (1942). Basic ideas and some recent results of the theory of testing statistical hypotheses. J. R. Stat. Soc. 105, 292–327. doi: 10.2307/2980436
Neyman, J. (1952). Lecture and Conferences on Mathematical Statistics and Probability. 2nd Edn . Washington, DC: US Department of Agriculture.
Nuijten, M. B., Hartgerink, C. H. J., van Assen, M. A. L. M., Epskamp, S., and Wicherts, J. M. (2016). The prevalence of statistical reporting errors in psychology (1985–2013). Behav. Res. Methods 48, 1205–1226. doi: 10.3758/s13428-015-0664-2
Open Science Collaboration (2015). Estimating the reproducibility of psychological science. Science 349:943. doi: 10.1126/science.aac4716
Perez, S., Massey-Allard, J., Butler, D., Ives, J., Bonn, D., Yee, N., et al. (2017). “Identifying productive inquiry in virtual labs using sequence mining,” in Artificial Intelligence in Education , eds E. André, R. Baker, X. Hu, M. M. T. Rodrigo, and B. du Boulay (Gewerbestrasse: Springer), 287–298. doi: 10.1007/978-3-319-61425-0_24
Pezzullo, L. G., Wiggins, J. B., Frankosky, M. H., Min, W., Boyer, K. E., Mott, B. W., et al. (2017). “Thanks Alisha, Keep in Touch: gender effects and engagement with virtual learning companions,” in Artificial Intelligence in Education , eds E. André, R. Baker, X. Hu, M. M. T. Rodrigo, and B. du Boulay (Gewerbestrasse: Springer), 299–310. doi: 10.1007/978-3-319-61425-0_25
Price, T. W., Zhi, R., and Barnes, T. (2017). “Hint generation under uncertainty: the effect of hint quality on help-seeking behavior,” in Artificial Intelligence in Education , eds E. André, R. Baker, X. Hu, M. M. T. Rodrigo, and B. du Boulay (Gewerbestrasse: Springer), 311–322. doi: 10.1007/978-3-319-61425-0_26
R Core Team (2019). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing . Available online at: https://www.R-project.org/
Randall, D., and Welser, C. (2018). The Irreproducibility Crisis of Modern Science. Causes, Consequences, and the Road to Reform. National Association of Scholars . Available online at: https://www.nas.org/reports/the-irreproducibility-crisis-of-modern-science
Reingold, J. (2015). Why Ed Tech is Currently ‘the Wild Wild West’. Fortune . Available online at: http://fortune.com/2015/11/04/ed-tech-at-fortune-globalforum-2015
Ritter, S., Anderson, J. R., Koedinger, K. R., and Corbett, A. (2007). Cognitive tutor: applied research in mathematics education. Psychonom. Bull. Rev. 14, 249–255. doi: 10.3758/BF03194060
Sedlmeier, P., and Gigerenzer, G. (1989). Do studies of statistical power have an effect on the power of studies? Psychol. Bull. 105, 309–316. doi: 10.1037//0033-2909.105.2.309
Sjödén, B., Lind, M., and Silvervarg, A. (2017). “Can a teachable agent influence how students respond to competition in an educational game?,” in Artificial Intelligence in Education , eds E. André, R. Baker, X. Hu, M. M. T. Rodrigo, and B. du Boulay (Gewerbestrasse: Springer), 347–358. doi: 10.1007/978-3-319-61425-0_29
Smaldino, P. E., and McElreath, R. (2016). The natural selection of bad science. R. Soc. Open Sci. 3:160384. doi: 10.1098/rsos.160384
Stark, P. B., and Saltelli, A. (2018). Cargo-cult statistics and scientific crisis. Significance 40–43. doi: 10.1111/j.1740-9713.2018.01174.x
Suppes, P. (1966). The uses of computers in education. Sci. Am. 215, 206–220. doi: 10.1038/scientificamerican0966-206
Talandron, M. M. P., Rodrigo, M. M. T., and Beck, J. E. (2017). “Modeling the incubation effect among students playing an educational game for physics,” in Artificial Intelligence in Education , eds E. André, R. Baker, X. Hu, M. M. T. Rodrigo, and B. du Boulay (Gewerbestrasse: Springer), 371–380. doi: 10.1007/978-3-319-61425-0_31
Waller, N. G., and Meehl, P. E. (1998). Multivariate Taxometric Procedures: Distinguishing Types From Continua . Thousand Oaks, CA: Sage Publications.
Worsley, P. M. (1957). The Trumpet Shall Sound: A Study of ‘Cargo Cults’ in Melanesia . New York, NY: Schocken Books.
Wright, D. B. (1998). Modelling clustered data in autobiographical memory research: the multilevel approach. Appl. Cognit. Psychol. 12, 339–357. doi: 10.1002/(SICI)1099-0720(199808)12:4<339::AID-ACP571>3.0.CO;2-D
Wright, D. B. (2017). Some limits using random slope models to measure student and school growth. Front. Educ. 2:58. doi: 10.3389/feduc.2017.00058
Wright, D. B. (2018). A framework for research on education with technology. Front. Educ. 3:21. doi: 10.3389/feduc.2018.00021
Wright, D. B. (2019). Allocation to groups: examples of Lord's paradox. Br. J. Educ. Psychol . doi: 10.1111/bjep.12300. [Epub ahead of print].
Xie, Y. (2015). Dynamic Documents With R and knitr. 2nd Edn . Boca Raton, FL: Chapman and Hall/CRC.
Keywords: EdTech, statistical methods, crisis in science, power, multilevel modeling, dichotomization
Citation: Wright DB (2019) Research Methods for Education With Technology: Four Concerns, Examples, and Recommendations. Front. Educ. 4:147. doi: 10.3389/feduc.2019.00147
Received: 01 September 2019; Accepted: 27 November 2019; Published: 10 December 2019.
Reviewed by:
Copyright © 2019 Wright. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY) . The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Daniel B. Wright, daniel.wright@unlv.edu ; dbrookswr@gmail.com
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Sweepstakes
- Guided Meditations
- Verywell Mind Insights
- 2024 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
How to Write a Great Hypothesis
Hypothesis Definition, Format, Examples, and Tips
Verywell / Alex Dos Diaz
- The Scientific Method
Hypothesis Format
Falsifiability of a hypothesis.
- Operationalization
Hypothesis Types
Hypotheses examples.
- Collecting Data
A hypothesis is a tentative statement about the relationship between two or more variables. It is a specific, testable prediction about what you expect to happen in a study. It is a preliminary answer to your question that helps guide the research process.
Consider a study designed to examine the relationship between sleep deprivation and test performance. The hypothesis might be: "This study is designed to assess the hypothesis that sleep-deprived people will perform worse on a test than individuals who are not sleep-deprived."
At a Glance
A hypothesis is crucial to scientific research because it offers a clear direction for what the researchers are looking to find. This allows them to design experiments to test their predictions and add to our scientific knowledge about the world. This article explores how a hypothesis is used in psychology research, how to write a good hypothesis, and the different types of hypotheses you might use.
The Hypothesis in the Scientific Method
In the scientific method , whether it involves research in psychology, biology, or some other area, a hypothesis represents what the researchers think will happen in an experiment. The scientific method involves the following steps:
- Forming a question
- Performing background research
- Creating a hypothesis
- Designing an experiment
- Collecting data
- Analyzing the results
- Drawing conclusions
- Communicating the results
The hypothesis is a prediction, but it involves more than a guess. Most of the time, the hypothesis begins with a question which is then explored through background research. At this point, researchers then begin to develop a testable hypothesis.
Unless you are creating an exploratory study, your hypothesis should always explain what you expect to happen.
In a study exploring the effects of a particular drug, the hypothesis might be that researchers expect the drug to have some type of effect on the symptoms of a specific illness. In psychology, the hypothesis might focus on how a certain aspect of the environment might influence a particular behavior.
Remember, a hypothesis does not have to be correct. While the hypothesis predicts what the researchers expect to see, the goal of the research is to determine whether this guess is right or wrong. When conducting an experiment, researchers might explore numerous factors to determine which ones might contribute to the ultimate outcome.
In many cases, researchers may find that the results of an experiment do not support the original hypothesis. When writing up these results, the researchers might suggest other options that should be explored in future studies.
In many cases, researchers might draw a hypothesis from a specific theory or build on previous research. For example, prior research has shown that stress can impact the immune system. So a researcher might hypothesize: "People with high-stress levels will be more likely to contract a common cold after being exposed to the virus than people who have low-stress levels."
In other instances, researchers might look at commonly held beliefs or folk wisdom. "Birds of a feather flock together" is one example of folk adage that a psychologist might try to investigate. The researcher might pose a specific hypothesis that "People tend to select romantic partners who are similar to them in interests and educational level."
Elements of a Good Hypothesis
So how do you write a good hypothesis? When trying to come up with a hypothesis for your research or experiments, ask yourself the following questions:
- Is your hypothesis based on your research on a topic?
- Can your hypothesis be tested?
- Does your hypothesis include independent and dependent variables?
Before you come up with a specific hypothesis, spend some time doing background research. Once you have completed a literature review, start thinking about potential questions you still have. Pay attention to the discussion section in the journal articles you read . Many authors will suggest questions that still need to be explored.
How to Formulate a Good Hypothesis
To form a hypothesis, you should take these steps:
- Collect as many observations about a topic or problem as you can.
- Evaluate these observations and look for possible causes of the problem.
- Create a list of possible explanations that you might want to explore.
- After you have developed some possible hypotheses, think of ways that you could confirm or disprove each hypothesis through experimentation. This is known as falsifiability.
In the scientific method , falsifiability is an important part of any valid hypothesis. In order to test a claim scientifically, it must be possible that the claim could be proven false.
Students sometimes confuse the idea of falsifiability with the idea that it means that something is false, which is not the case. What falsifiability means is that if something was false, then it is possible to demonstrate that it is false.
One of the hallmarks of pseudoscience is that it makes claims that cannot be refuted or proven false.
The Importance of Operational Definitions
A variable is a factor or element that can be changed and manipulated in ways that are observable and measurable. However, the researcher must also define how the variable will be manipulated and measured in the study.
Operational definitions are specific definitions for all relevant factors in a study. This process helps make vague or ambiguous concepts detailed and measurable.
For example, a researcher might operationally define the variable " test anxiety " as the results of a self-report measure of anxiety experienced during an exam. A "study habits" variable might be defined by the amount of studying that actually occurs as measured by time.
These precise descriptions are important because many things can be measured in various ways. Clearly defining these variables and how they are measured helps ensure that other researchers can replicate your results.
Replicability
One of the basic principles of any type of scientific research is that the results must be replicable.
Replication means repeating an experiment in the same way to produce the same results. By clearly detailing the specifics of how the variables were measured and manipulated, other researchers can better understand the results and repeat the study if needed.
Some variables are more difficult than others to define. For example, how would you operationally define a variable such as aggression ? For obvious ethical reasons, researchers cannot create a situation in which a person behaves aggressively toward others.
To measure this variable, the researcher must devise a measurement that assesses aggressive behavior without harming others. The researcher might utilize a simulated task to measure aggressiveness in this situation.
Hypothesis Checklist
- Does your hypothesis focus on something that you can actually test?
- Does your hypothesis include both an independent and dependent variable?
- Can you manipulate the variables?
- Can your hypothesis be tested without violating ethical standards?
The hypothesis you use will depend on what you are investigating and hoping to find. Some of the main types of hypotheses that you might use include:
- Simple hypothesis : This type of hypothesis suggests there is a relationship between one independent variable and one dependent variable.
- Complex hypothesis : This type suggests a relationship between three or more variables, such as two independent and dependent variables.
- Null hypothesis : This hypothesis suggests no relationship exists between two or more variables.
- Alternative hypothesis : This hypothesis states the opposite of the null hypothesis.
- Statistical hypothesis : This hypothesis uses statistical analysis to evaluate a representative population sample and then generalizes the findings to the larger group.
- Logical hypothesis : This hypothesis assumes a relationship between variables without collecting data or evidence.
A hypothesis often follows a basic format of "If {this happens} then {this will happen}." One way to structure your hypothesis is to describe what will happen to the dependent variable if you change the independent variable .
The basic format might be: "If {these changes are made to a certain independent variable}, then we will observe {a change in a specific dependent variable}."
A few examples of simple hypotheses:
- "Students who eat breakfast will perform better on a math exam than students who do not eat breakfast."
- "Students who experience test anxiety before an English exam will get lower scores than students who do not experience test anxiety."
- "Motorists who talk on the phone while driving will be more likely to make errors on a driving course than those who do not talk on the phone."
- "Children who receive a new reading intervention will have higher reading scores than students who do not receive the intervention."
Examples of a complex hypothesis include:
- "People with high-sugar diets and sedentary activity levels are more likely to develop depression."
- "Younger people who are regularly exposed to green, outdoor areas have better subjective well-being than older adults who have limited exposure to green spaces."
Examples of a null hypothesis include:
- "There is no difference in anxiety levels between people who take St. John's wort supplements and those who do not."
- "There is no difference in scores on a memory recall task between children and adults."
- "There is no difference in aggression levels between children who play first-person shooter games and those who do not."
Examples of an alternative hypothesis:
- "People who take St. John's wort supplements will have less anxiety than those who do not."
- "Adults will perform better on a memory task than children."
- "Children who play first-person shooter games will show higher levels of aggression than children who do not."
Collecting Data on Your Hypothesis
Once a researcher has formed a testable hypothesis, the next step is to select a research design and start collecting data. The research method depends largely on exactly what they are studying. There are two basic types of research methods: descriptive research and experimental research.
Descriptive Research Methods
Descriptive research such as case studies , naturalistic observations , and surveys are often used when conducting an experiment is difficult or impossible. These methods are best used to describe different aspects of a behavior or psychological phenomenon.
Once a researcher has collected data using descriptive methods, a correlational study can examine how the variables are related. This research method might be used to investigate a hypothesis that is difficult to test experimentally.
Experimental Research Methods
Experimental methods are used to demonstrate causal relationships between variables. In an experiment, the researcher systematically manipulates a variable of interest (known as the independent variable) and measures the effect on another variable (known as the dependent variable).
Unlike correlational studies, which can only be used to determine if there is a relationship between two variables, experimental methods can be used to determine the actual nature of the relationship—whether changes in one variable actually cause another to change.
The hypothesis is a critical part of any scientific exploration. It represents what researchers expect to find in a study or experiment. In situations where the hypothesis is unsupported by the research, the research still has value. Such research helps us better understand how different aspects of the natural world relate to one another. It also helps us develop new hypotheses that can then be tested in the future.
Thompson WH, Skau S. On the scope of scientific hypotheses . R Soc Open Sci . 2023;10(8):230607. doi:10.1098/rsos.230607
Taran S, Adhikari NKJ, Fan E. Falsifiability in medicine: what clinicians can learn from Karl Popper [published correction appears in Intensive Care Med. 2021 Jun 17;:]. Intensive Care Med . 2021;47(9):1054-1056. doi:10.1007/s00134-021-06432-z
Eyler AA. Research Methods for Public Health . 1st ed. Springer Publishing Company; 2020. doi:10.1891/9780826182067.0004
Nosek BA, Errington TM. What is replication ? PLoS Biol . 2020;18(3):e3000691. doi:10.1371/journal.pbio.3000691
Aggarwal R, Ranganathan P. Study designs: Part 2 - Descriptive studies . Perspect Clin Res . 2019;10(1):34-36. doi:10.4103/picr.PICR_154_18
Nevid J. Psychology: Concepts and Applications. Wadworth, 2013.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
- History & Society
- Science & Tech
- Biographies
- Animals & Nature
- Geography & Travel
- Arts & Culture
- Games & Quizzes
- On This Day
- One Good Fact
- New Articles
- Lifestyles & Social Issues
- Philosophy & Religion
- Politics, Law & Government
- World History
- Health & Medicine
- Browse Biographies
- Birds, Reptiles & Other Vertebrates
- Bugs, Mollusks & Other Invertebrates
- Environment
- Fossils & Geologic Time
- Entertainment & Pop Culture
- Sports & Recreation
- Visual Arts
- Demystified
- Image Galleries
- Infographics
- Top Questions
- Britannica Kids
- Saving Earth
- Space Next 50
- Student Center

- Where was science invented?
- When did science begin?

scientific hypothesis
Our editors will review what you’ve submitted and determine whether to revise the article.
- National Center for Biotechnology Information - PubMed Central - On the scope of scientific hypotheses
- LiveScience - What is a scientific hypothesis?
- The Royal Society - Open Science - On the scope of scientific hypotheses

scientific hypothesis , an idea that proposes a tentative explanation about a phenomenon or a narrow set of phenomena observed in the natural world. The two primary features of a scientific hypothesis are falsifiability and testability, which are reflected in an “If…then” statement summarizing the idea and in the ability to be supported or refuted through observation and experimentation. The notion of the scientific hypothesis as both falsifiable and testable was advanced in the mid-20th century by Austrian-born British philosopher Karl Popper .
The formulation and testing of a hypothesis is part of the scientific method , the approach scientists use when attempting to understand and test ideas about natural phenomena. The generation of a hypothesis frequently is described as a creative process and is based on existing scientific knowledge, intuition , or experience. Therefore, although scientific hypotheses commonly are described as educated guesses, they actually are more informed than a guess. In addition, scientists generally strive to develop simple hypotheses, since these are easier to test relative to hypotheses that involve many different variables and potential outcomes. Such complex hypotheses may be developed as scientific models ( see scientific modeling ).
Depending on the results of scientific evaluation, a hypothesis typically is either rejected as false or accepted as true. However, because a hypothesis inherently is falsifiable, even hypotheses supported by scientific evidence and accepted as true are susceptible to rejection later, when new evidence has become available. In some instances, rather than rejecting a hypothesis because it has been falsified by new evidence, scientists simply adapt the existing idea to accommodate the new information. In this sense a hypothesis is never incorrect but only incomplete.
The investigation of scientific hypotheses is an important component in the development of scientific theory . Hence, hypotheses differ fundamentally from theories; whereas the former is a specific tentative explanation and serves as the main tool by which scientists gather data, the latter is a broad general explanation that incorporates data from many different scientific investigations undertaken to explore hypotheses.
Countless hypotheses have been developed and tested throughout the history of science . Several examples include the idea that living organisms develop from nonliving matter, which formed the basis of spontaneous generation , a hypothesis that ultimately was disproved (first in 1668, with the experiments of Italian physician Francesco Redi , and later in 1859, with the experiments of French chemist and microbiologist Louis Pasteur ); the concept proposed in the late 19th century that microorganisms cause certain diseases (now known as germ theory ); and the notion that oceanic crust forms along submarine mountain zones and spreads laterally away from them ( seafloor spreading hypothesis ).
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Hypothesis Testing | A Step-by-Step Guide with Easy Examples
Published on November 8, 2019 by Rebecca Bevans . Revised on June 22, 2023.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics . It is most often used by scientists to test specific predictions, called hypotheses, that arise from theories.
There are 5 main steps in hypothesis testing:
- State your research hypothesis as a null hypothesis and alternate hypothesis (H o ) and (H a or H 1 ).
- Collect data in a way designed to test the hypothesis.
- Perform an appropriate statistical test .
- Decide whether to reject or fail to reject your null hypothesis.
- Present the findings in your results and discussion section.
Though the specific details might vary, the procedure you will use when testing a hypothesis will always follow some version of these steps.
Table of contents
Step 1: state your null and alternate hypothesis, step 2: collect data, step 3: perform a statistical test, step 4: decide whether to reject or fail to reject your null hypothesis, step 5: present your findings, other interesting articles, frequently asked questions about hypothesis testing.
After developing your initial research hypothesis (the prediction that you want to investigate), it is important to restate it as a null (H o ) and alternate (H a ) hypothesis so that you can test it mathematically.
The alternate hypothesis is usually your initial hypothesis that predicts a relationship between variables. The null hypothesis is a prediction of no relationship between the variables you are interested in.
- H 0 : Men are, on average, not taller than women. H a : Men are, on average, taller than women.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
For a statistical test to be valid , it is important to perform sampling and collect data in a way that is designed to test your hypothesis. If your data are not representative, then you cannot make statistical inferences about the population you are interested in.
There are a variety of statistical tests available, but they are all based on the comparison of within-group variance (how spread out the data is within a category) versus between-group variance (how different the categories are from one another).
If the between-group variance is large enough that there is little or no overlap between groups, then your statistical test will reflect that by showing a low p -value . This means it is unlikely that the differences between these groups came about by chance.
Alternatively, if there is high within-group variance and low between-group variance, then your statistical test will reflect that with a high p -value. This means it is likely that any difference you measure between groups is due to chance.
Your choice of statistical test will be based on the type of variables and the level of measurement of your collected data .
- an estimate of the difference in average height between the two groups.
- a p -value showing how likely you are to see this difference if the null hypothesis of no difference is true.
Based on the outcome of your statistical test, you will have to decide whether to reject or fail to reject your null hypothesis.
In most cases you will use the p -value generated by your statistical test to guide your decision. And in most cases, your predetermined level of significance for rejecting the null hypothesis will be 0.05 – that is, when there is a less than 5% chance that you would see these results if the null hypothesis were true.
In some cases, researchers choose a more conservative level of significance, such as 0.01 (1%). This minimizes the risk of incorrectly rejecting the null hypothesis ( Type I error ).
The results of hypothesis testing will be presented in the results and discussion sections of your research paper , dissertation or thesis .
In the results section you should give a brief summary of the data and a summary of the results of your statistical test (for example, the estimated difference between group means and associated p -value). In the discussion , you can discuss whether your initial hypothesis was supported by your results or not.
In the formal language of hypothesis testing, we talk about rejecting or failing to reject the null hypothesis. You will probably be asked to do this in your statistics assignments.
However, when presenting research results in academic papers we rarely talk this way. Instead, we go back to our alternate hypothesis (in this case, the hypothesis that men are on average taller than women) and state whether the result of our test did or did not support the alternate hypothesis.
If your null hypothesis was rejected, this result is interpreted as “supported the alternate hypothesis.”
These are superficial differences; you can see that they mean the same thing.
You might notice that we don’t say that we reject or fail to reject the alternate hypothesis . This is because hypothesis testing is not designed to prove or disprove anything. It is only designed to test whether a pattern we measure could have arisen spuriously, or by chance.
If we reject the null hypothesis based on our research (i.e., we find that it is unlikely that the pattern arose by chance), then we can say our test lends support to our hypothesis . But if the pattern does not pass our decision rule, meaning that it could have arisen by chance, then we say the test is inconsistent with our hypothesis .
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Descriptive statistics
- Measures of central tendency
- Correlation coefficient
Methodology
- Cluster sampling
- Stratified sampling
- Types of interviews
- Cohort study
- Thematic analysis
Research bias
- Implicit bias
- Cognitive bias
- Survivorship bias
- Availability heuristic
- Nonresponse bias
- Regression to the mean
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 22). Hypothesis Testing | A Step-by-Step Guide with Easy Examples. Scribbr. Retrieved September 3, 2024, from https://www.scribbr.com/statistics/hypothesis-testing/
Is this article helpful?

Rebecca Bevans
Other students also liked, choosing the right statistical test | types & examples, understanding p values | definition and examples, what is your plagiarism score.
- Translators
- Graphic Designers
Please enter the email address you used for your account. Your sign in information will be sent to your email address after it has been verified.
100 Hypothesis Examples Across Various Academic Fields

A hypothesis is a statement or proposition that is made for the purpose of testing through empirical research. It represents an educated guess or prediction that can be tested through observation and experimentation. A hypothesis is often formulated using a logical construct of "if-then" statements, allowing researchers to set up experiments to determine its validity. It serves as the foundation of a scientific inquiry, providing a clear focus and direction for the study. In essence, a hypothesis is a provisional answer to a research question , which is then subjected to rigorous testing to determine its accuracy.
In this blog post, we'll explore 100 different hypothesis examples, showing you how these simple statements set the stage for discovery in various academic fields. From the mysteries of chemical reactions to the complexities of human behavior, hypotheses are used to kickstart research in numerous disciplines. Whether you're new to the world of academia or just curious about how ideas are tested, these examples will offer insight into the fundamental role hypotheses play in learning and exploration.
- If a plant is given more sunlight, then it will grow faster.
- If an animal's environment is altered, then its behavior will change.
- If a cell is exposed to a toxin, then its function will be impaired.
- If a species is introduced to a new ecosystem, then it may become invasive.
- If an antibiotic is applied to a bacterial culture, then growth will be inhibited.
- If a gene is mutated, then the corresponding protein may become nonfunctional.
- If a pond's water temperature rises, then the algae population will increase.
- If a bird species' habitat is destroyed, then its population will decrease.
- If a mammal is given a high-fat diet, then its cholesterol levels will rise.
- If human stem cells are treated with specific factors, then they will differentiate into targeted cell types.
- If the concentration of a reactant is increased, then the rate of reaction will increase.
- If a metal is placed in a solution of a salt of a less reactive metal, then a displacement reaction will occur.
- If a solution's pH is lowered, then the concentration of hydrogen ions will increase.
- If a gas is cooled at constant pressure, then its volume will decrease according to Charles's law.
- If an endothermic reaction is heated, then the equilibrium position will shift to favor the products.
- If an enzyme is added to a reaction, then the reaction rate will increase due to the lower activation energy.
- If the pressure on a gas is increased at constant temperature, then the volume will decrease according to Boyle's law.
- If a non-polar molecule is added to water, then it will not dissolve due to water's polarity.
- If a piece of litmus paper is placed in a basic solution, then the color of the paper will turn blue.
- If an electric current is passed through a salt solution, then the solution will undergo electrolysis and break down into its components.
Computer science
- If a new algorithm is applied to a sorting problem, then the computational complexity will decrease.
- If multi-factor authentication is implemented, then the security of a system will increase.
- If a machine learning model is trained with more diverse data, then its predictive accuracy will improve.
- If the bandwidth of a network is increased, then the data transmission rate will be faster.
- If a user interface is redesigned following usability guidelines, then user satisfaction and efficiency will increase.
- If a specific optimization technique is applied to a database query, then the retrieval time will be reduced.
- If a new cooling system is used in a data center, then energy consumption will decrease.
- If parallel processing is implemented in a computational task, then the processing time will be reduced.
- If a software development team adopts Agile methodologies, then the project delivery time will be shortened.
- If a more advanced error correction code is used in data transmission, then the error rate will decrease.
- If the interest rate is lowered, then consumer spending will increase.
- If the minimum wage is raised, then unemployment may increase among low-skilled workers.
- If government spending is increased, then the Gross Domestic Product (GDP) may grow.
- If taxes on luxury goods are raised, then consumption of those goods may decrease.
- If a country's currency is devalued, then its exports will become more competitive.
- If inflation is high, then the central bank may increase interest rates to control it.
- If consumer confidence is high, then spending in the economy will likely increase.
- If barriers to entry in a market are reduced, then competition will likely increase.
- If a firm engages in monopolistic practices, then consumer welfare may decrease.
- If unemployment benefits are extended, then the unemployment rate may be temporarily affected.
- If class sizes are reduced, then individual student performance may improve.
- If teachers receive ongoing professional development, then teaching quality will increase.
- If schools implement a comprehensive literacy program, then reading levels among students will rise.
- If parents are actively involved in their children's education, then students' academic achievement may increase.
- If schools provide more access to extracurricular activities, then student engagement and retention may improve.
- If educational technology is integrated into the classroom, then learning outcomes may enhance.
- If a school adopts a zero-tolerance policy on bullying, then the incidence of bullying will decrease.
- If schools provide nutritious meals, then student concentration and performance may improve.
- If a curriculum is designed to include diverse cultural perspectives, then student understanding of different cultures will increase.
- If schools implement individualized learning plans, then students with special needs will achieve better educational outcomes.
Environmental science
- If deforestation rates continue to rise, then biodiversity in the area will decrease.
- If carbon dioxide emissions are reduced, then the rate of global warming may decrease.
- If a water body is polluted with nutrients, then algal blooms may occur, leading to eutrophication.
- If renewable energy sources are used more extensively, then dependency on fossil fuels will decrease.
- If urban areas implement green spaces, then the urban heat island effect may be reduced.
- If protective measures are not implemented, then endangered species may become extinct.
- If waste recycling practices are increased, then landfill usage and waste pollution may decrease.
- If air quality regulations are enforced, then respiratory health issues in the population may decrease.
- If soil erosion control measures are not implemented, then agricultural land fertility may decrease.
- If ocean temperatures continue to rise, then coral reefs may experience more frequent bleaching events.
- If a new chemotherapy drug is administered to cancer patients, then tumor size will decrease more effectively.
- If a specific exercise regimen is followed by osteoarthritis patients, then joint mobility will improve.
- If a population is exposed to higher levels of air pollution, then respiratory diseases such as asthma will increase.
- If a novel surgical technique is utilized in cardiac surgery, then patient recovery times will be shortened.
- If a targeted screening program is implemented for a specific genetic disorder, then early detection and intervention rates will increase.
- If a community's water supply is fortified with fluoride, then dental cavity rates in children will decrease.
- If an improved vaccination schedule is followed in a pediatric population, then the incidence of preventable childhood diseases will decline.
- If nutritional supplements are provided to malnourished individuals, then general health and immune function will improve.
- If stricter infection control protocols are implemented in hospitals, then the rate of hospital-acquired infections will decrease.
- If organ transplant recipients are given a new immunosuppressant drug, then organ rejection rates will decrease.
- If a person is exposed to violent media, then their aggression levels may increase.
- If a child is given positive reinforcement, then desired behaviors will be more likely to be repeated.
- If an individual suffers from anxiety, then their performance on tasks under pressure may decrease.
- If a patient is treated with cognitive-behavioral therapy, then symptoms of depression may reduce.
- If a person lacks sleep, then their cognitive functions and decision-making abilities will decline.
- If an individual's self-esteem is increased, then their overall life satisfaction may improve.
- If a person is exposed to a traumatic event, then they may develop symptoms of PTSD.
- If social support is provided to an individual, then their ability to cope with stress will improve.
- If a group works collaboratively, then they may exhibit improved problem-solving abilities.
- If an individual is given autonomy in their work, then their job satisfaction and motivation will increase.
- If the velocity of an object is increased, then the kinetic energy will also increase.
- If the temperature of a gas is increased at constant pressure, then the volume will increase.
- If the mass of an object is doubled, then the gravitational force it exerts will also double.
- If the frequency of a wave is increased, then the energy it carries will increase.
- If a magnet's distance from a metal object is decreased, then the magnetic force will increase.
- If the angle of incidence equals the angle of reflection, then the law of reflection holds true.
- If the resistance in an electrical circuit is increased, then the current will decrease.
- If the force applied to a spring is doubled, then the extension of the spring will also double.
- If a mirror is concave, then it will focus parallel rays to a point.
- If a body is in uniform circular motion, then the net force toward the center is providing the centripetal acceleration.
- If educational opportunities are equally distributed in a society, then social mobility will increase.
- If community policing strategies are implemented, then trust between law enforcement and the community may improve.
- If social media usage increases among teenagers, then face-to-face social interaction may decrease.
- If gender wage gap policies are enforced, then disparities in earnings between men and women will decrease.
- If a society emphasizes individualistic values, then community engagement and collective responsibility may decline.
- If affordable housing initiatives are implemented in urban areas, then homelessness rates may decrease.
- If a minority group is represented in media, then stereotypes and prejudices toward that group may decrease.
- If a culture promotes work-life balance, then overall life satisfaction among its citizens may increase.
- If increased funding is provided to community centers in underserved neighborhoods, then social cohesion and community engagement may improve.
- If legislation is passed to protect the rights of LGBTQ+ individuals, then discrimination and stigma may decrease in society.
In the exploration of various academic disciplines, hypotheses play a crucial role as foundational statements that guide research and inquiry. From understanding complex biological processes to navigating the nuances of human behavior in sociology, hypotheses serve as testable predictions that shape the direction of scientific investigation. The examples provided across the fields of medicine, computer science, sociology, and education illustrate the diverse applications and importance of hypotheses in shaping our understanding of the world. Whether improving medical treatments, enhancing technological systems, fostering social equality, or elevating educational practices, hypotheses remain central to scientific progress and societal advancement. By formulating clear and measurable hypotheses, researchers can continue to unravel complex phenomena, contribute to their fields, and ultimately enrich human knowledge and well-being.
Header image by Qunica .

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- v.53(4); 2010 Aug
Research questions, hypotheses and objectives
Patricia farrugia.
* Michael G. DeGroote School of Medicine, the
Bradley A. Petrisor
† Division of Orthopaedic Surgery and the
Forough Farrokhyar
‡ Departments of Surgery and
§ Clinical Epidemiology and Biostatistics, McMaster University, Hamilton, Ont
Mohit Bhandari
There is an increasing familiarity with the principles of evidence-based medicine in the surgical community. As surgeons become more aware of the hierarchy of evidence, grades of recommendations and the principles of critical appraisal, they develop an increasing familiarity with research design. Surgeons and clinicians are looking more and more to the literature and clinical trials to guide their practice; as such, it is becoming a responsibility of the clinical research community to attempt to answer questions that are not only well thought out but also clinically relevant. The development of the research question, including a supportive hypothesis and objectives, is a necessary key step in producing clinically relevant results to be used in evidence-based practice. A well-defined and specific research question is more likely to help guide us in making decisions about study design and population and subsequently what data will be collected and analyzed. 1
Objectives of this article
In this article, we discuss important considerations in the development of a research question and hypothesis and in defining objectives for research. By the end of this article, the reader will be able to appreciate the significance of constructing a good research question and developing hypotheses and research objectives for the successful design of a research study. The following article is divided into 3 sections: research question, research hypothesis and research objectives.
Research question
Interest in a particular topic usually begins the research process, but it is the familiarity with the subject that helps define an appropriate research question for a study. 1 Questions then arise out of a perceived knowledge deficit within a subject area or field of study. 2 Indeed, Haynes suggests that it is important to know “where the boundary between current knowledge and ignorance lies.” 1 The challenge in developing an appropriate research question is in determining which clinical uncertainties could or should be studied and also rationalizing the need for their investigation.
Increasing one’s knowledge about the subject of interest can be accomplished in many ways. Appropriate methods include systematically searching the literature, in-depth interviews and focus groups with patients (and proxies) and interviews with experts in the field. In addition, awareness of current trends and technological advances can assist with the development of research questions. 2 It is imperative to understand what has been studied about a topic to date in order to further the knowledge that has been previously gathered on a topic. Indeed, some granting institutions (e.g., Canadian Institute for Health Research) encourage applicants to conduct a systematic review of the available evidence if a recent review does not already exist and preferably a pilot or feasibility study before applying for a grant for a full trial.
In-depth knowledge about a subject may generate a number of questions. It then becomes necessary to ask whether these questions can be answered through one study or if more than one study needed. 1 Additional research questions can be developed, but several basic principles should be taken into consideration. 1 All questions, primary and secondary, should be developed at the beginning and planning stages of a study. Any additional questions should never compromise the primary question because it is the primary research question that forms the basis of the hypothesis and study objectives. It must be kept in mind that within the scope of one study, the presence of a number of research questions will affect and potentially increase the complexity of both the study design and subsequent statistical analyses, not to mention the actual feasibility of answering every question. 1 A sensible strategy is to establish a single primary research question around which to focus the study plan. 3 In a study, the primary research question should be clearly stated at the end of the introduction of the grant proposal, and it usually specifies the population to be studied, the intervention to be implemented and other circumstantial factors. 4
Hulley and colleagues 2 have suggested the use of the FINER criteria in the development of a good research question ( Box 1 ). The FINER criteria highlight useful points that may increase the chances of developing a successful research project. A good research question should specify the population of interest, be of interest to the scientific community and potentially to the public, have clinical relevance and further current knowledge in the field (and of course be compliant with the standards of ethical boards and national research standards).
FINER criteria for a good research question
| Feasible | ||
| Interesting | ||
| Novel | ||
| Ethical | ||
| Relevant |
Adapted with permission from Wolters Kluwer Health. 2
Whereas the FINER criteria outline the important aspects of the question in general, a useful format to use in the development of a specific research question is the PICO format — consider the population (P) of interest, the intervention (I) being studied, the comparison (C) group (or to what is the intervention being compared) and the outcome of interest (O). 3 , 5 , 6 Often timing (T) is added to PICO ( Box 2 ) — that is, “Over what time frame will the study take place?” 1 The PICOT approach helps generate a question that aids in constructing the framework of the study and subsequently in protocol development by alluding to the inclusion and exclusion criteria and identifying the groups of patients to be included. Knowing the specific population of interest, intervention (and comparator) and outcome of interest may also help the researcher identify an appropriate outcome measurement tool. 7 The more defined the population of interest, and thus the more stringent the inclusion and exclusion criteria, the greater the effect on the interpretation and subsequent applicability and generalizability of the research findings. 1 , 2 A restricted study population (and exclusion criteria) may limit bias and increase the internal validity of the study; however, this approach will limit external validity of the study and, thus, the generalizability of the findings to the practical clinical setting. Conversely, a broadly defined study population and inclusion criteria may be representative of practical clinical practice but may increase bias and reduce the internal validity of the study.
PICOT criteria 1
| Population (patients) | ||
| Intervention (for intervention studies only) | ||
| Comparison group | ||
| Outcome of interest | ||
| Time |
A poorly devised research question may affect the choice of study design, potentially lead to futile situations and, thus, hamper the chance of determining anything of clinical significance, which will then affect the potential for publication. Without devoting appropriate resources to developing the research question, the quality of the study and subsequent results may be compromised. During the initial stages of any research study, it is therefore imperative to formulate a research question that is both clinically relevant and answerable.
Research hypothesis
The primary research question should be driven by the hypothesis rather than the data. 1 , 2 That is, the research question and hypothesis should be developed before the start of the study. This sounds intuitive; however, if we take, for example, a database of information, it is potentially possible to perform multiple statistical comparisons of groups within the database to find a statistically significant association. This could then lead one to work backward from the data and develop the “question.” This is counterintuitive to the process because the question is asked specifically to then find the answer, thus collecting data along the way (i.e., in a prospective manner). Multiple statistical testing of associations from data previously collected could potentially lead to spuriously positive findings of association through chance alone. 2 Therefore, a good hypothesis must be based on a good research question at the start of a trial and, indeed, drive data collection for the study.
The research or clinical hypothesis is developed from the research question and then the main elements of the study — sampling strategy, intervention (if applicable), comparison and outcome variables — are summarized in a form that establishes the basis for testing, statistical and ultimately clinical significance. 3 For example, in a research study comparing computer-assisted acetabular component insertion versus freehand acetabular component placement in patients in need of total hip arthroplasty, the experimental group would be computer-assisted insertion and the control/conventional group would be free-hand placement. The investigative team would first state a research hypothesis. This could be expressed as a single outcome (e.g., computer-assisted acetabular component placement leads to improved functional outcome) or potentially as a complex/composite outcome; that is, more than one outcome (e.g., computer-assisted acetabular component placement leads to both improved radiographic cup placement and improved functional outcome).
However, when formally testing statistical significance, the hypothesis should be stated as a “null” hypothesis. 2 The purpose of hypothesis testing is to make an inference about the population of interest on the basis of a random sample taken from that population. The null hypothesis for the preceding research hypothesis then would be that there is no difference in mean functional outcome between the computer-assisted insertion and free-hand placement techniques. After forming the null hypothesis, the researchers would form an alternate hypothesis stating the nature of the difference, if it should appear. The alternate hypothesis would be that there is a difference in mean functional outcome between these techniques. At the end of the study, the null hypothesis is then tested statistically. If the findings of the study are not statistically significant (i.e., there is no difference in functional outcome between the groups in a statistical sense), we cannot reject the null hypothesis, whereas if the findings were significant, we can reject the null hypothesis and accept the alternate hypothesis (i.e., there is a difference in mean functional outcome between the study groups), errors in testing notwithstanding. In other words, hypothesis testing confirms or refutes the statement that the observed findings did not occur by chance alone but rather occurred because there was a true difference in outcomes between these surgical procedures. The concept of statistical hypothesis testing is complex, and the details are beyond the scope of this article.
Another important concept inherent in hypothesis testing is whether the hypotheses will be 1-sided or 2-sided. A 2-sided hypothesis states that there is a difference between the experimental group and the control group, but it does not specify in advance the expected direction of the difference. For example, we asked whether there is there an improvement in outcomes with computer-assisted surgery or whether the outcomes worse with computer-assisted surgery. We presented a 2-sided test in the above example because we did not specify the direction of the difference. A 1-sided hypothesis states a specific direction (e.g., there is an improvement in outcomes with computer-assisted surgery). A 2-sided hypothesis should be used unless there is a good justification for using a 1-sided hypothesis. As Bland and Atlman 8 stated, “One-sided hypothesis testing should never be used as a device to make a conventionally nonsignificant difference significant.”
The research hypothesis should be stated at the beginning of the study to guide the objectives for research. Whereas the investigators may state the hypothesis as being 1-sided (there is an improvement with treatment), the study and investigators must adhere to the concept of clinical equipoise. According to this principle, a clinical (or surgical) trial is ethical only if the expert community is uncertain about the relative therapeutic merits of the experimental and control groups being evaluated. 9 It means there must exist an honest and professional disagreement among expert clinicians about the preferred treatment. 9
Designing a research hypothesis is supported by a good research question and will influence the type of research design for the study. Acting on the principles of appropriate hypothesis development, the study can then confidently proceed to the development of the research objective.
Research objective
The primary objective should be coupled with the hypothesis of the study. Study objectives define the specific aims of the study and should be clearly stated in the introduction of the research protocol. 7 From our previous example and using the investigative hypothesis that there is a difference in functional outcomes between computer-assisted acetabular component placement and free-hand placement, the primary objective can be stated as follows: this study will compare the functional outcomes of computer-assisted acetabular component insertion versus free-hand placement in patients undergoing total hip arthroplasty. Note that the study objective is an active statement about how the study is going to answer the specific research question. Objectives can (and often do) state exactly which outcome measures are going to be used within their statements. They are important because they not only help guide the development of the protocol and design of study but also play a role in sample size calculations and determining the power of the study. 7 These concepts will be discussed in other articles in this series.
From the surgeon’s point of view, it is important for the study objectives to be focused on outcomes that are important to patients and clinically relevant. For example, the most methodologically sound randomized controlled trial comparing 2 techniques of distal radial fixation would have little or no clinical impact if the primary objective was to determine the effect of treatment A as compared to treatment B on intraoperative fluoroscopy time. However, if the objective was to determine the effect of treatment A as compared to treatment B on patient functional outcome at 1 year, this would have a much more significant impact on clinical decision-making. Second, more meaningful surgeon–patient discussions could ensue, incorporating patient values and preferences with the results from this study. 6 , 7 It is the precise objective and what the investigator is trying to measure that is of clinical relevance in the practical setting.
The following is an example from the literature about the relation between the research question, hypothesis and study objectives:
Study: Warden SJ, Metcalf BR, Kiss ZS, et al. Low-intensity pulsed ultrasound for chronic patellar tendinopathy: a randomized, double-blind, placebo-controlled trial. Rheumatology 2008;47:467–71.
Research question: How does low-intensity pulsed ultrasound (LIPUS) compare with a placebo device in managing the symptoms of skeletally mature patients with patellar tendinopathy?
Research hypothesis: Pain levels are reduced in patients who receive daily active-LIPUS (treatment) for 12 weeks compared with individuals who receive inactive-LIPUS (placebo).
Objective: To investigate the clinical efficacy of LIPUS in the management of patellar tendinopathy symptoms.
The development of the research question is the most important aspect of a research project. A research project can fail if the objectives and hypothesis are poorly focused and underdeveloped. Useful tips for surgical researchers are provided in Box 3 . Designing and developing an appropriate and relevant research question, hypothesis and objectives can be a difficult task. The critical appraisal of the research question used in a study is vital to the application of the findings to clinical practice. Focusing resources, time and dedication to these 3 very important tasks will help to guide a successful research project, influence interpretation of the results and affect future publication efforts.
Tips for developing research questions, hypotheses and objectives for research studies
- Perform a systematic literature review (if one has not been done) to increase knowledge and familiarity with the topic and to assist with research development.
- Learn about current trends and technological advances on the topic.
- Seek careful input from experts, mentors, colleagues and collaborators to refine your research question as this will aid in developing the research question and guide the research study.
- Use the FINER criteria in the development of the research question.
- Ensure that the research question follows PICOT format.
- Develop a research hypothesis from the research question.
- Develop clear and well-defined primary and secondary (if needed) objectives.
- Ensure that the research question and objectives are answerable, feasible and clinically relevant.
FINER = feasible, interesting, novel, ethical, relevant; PICOT = population (patients), intervention (for intervention studies only), comparison group, outcome of interest, time.
Competing interests: No funding was received in preparation of this paper. Dr. Bhandari was funded, in part, by a Canada Research Chair, McMaster University.
IMAGES
VIDEO
COMMENTS
A good alternative hypothesis example is "Attending physiotherapy sessions improves athletes' on-field performance." or "Water evaporates at 100°C. ... Example - Research question: What are the factors that influence the adoption of the new technology? Research hypothesis: There is a positive relationship between age, education and ...
15 Hypothesis Examples. A hypothesis is defined as a testable prediction, and is used primarily in scientific experiments as a potential or predicted outcome that scientists attempt to prove or disprove (Atkinson et al., 2021; Tan, 2022). In my types of hypothesis article, I outlined 13 different hypotheses, including the directional hypothesis ...
Here are some good research hypothesis examples: "The use of a specific type of therapy will lead to a reduction in symptoms of depression in individuals with a history of major depressive disorder.". "Providing educational interventions on healthy eating habits will result in weight loss in overweight individuals.".
Developing a hypothesis (with example) Step 1. Ask a question. Writing a hypothesis begins with a research question that you want to answer. The question should be focused, specific, and researchable within the constraints of your project. Example: Research question.
4 Comparative Hypotheses for Technology Analysis. tire cords, telephone versus telegraph usage, etc. Overall, then, a predator-prey interaction has. an emerging technology in the role of predator ...
A solid research hypothesis, informed by a good research question, influences the research design and paves the way for defining clear research objectives. ... Example: "Implementing technology-based learning tools (IV) is likely to enhance student engagement in the classroom (DV), because interactive and multimedia content increases student ...
Hypotheses in research need to satisfy specific criteria to be considered scientifically rigorous. Here are the most notable qualities of a strong hypothesis: Testability: Ensure the hypothesis allows you to work towards observable and testable results. Brevity and objectivity: Present your hypothesis as a brief statement and avoid wordiness.
A research hypothesis (also called a scientific hypothesis) is a statement about the expected outcome of a study (for example, a dissertation or thesis). To constitute a quality hypothesis, the statement needs to have three attributes - specificity, clarity and testability. Let's take a look at these more closely.
To explore the aptness of this framework, I offer the following seven hypotheses. 1. Ed tech supports and replicates the university's mission, using the methods characteristic of scholarship in general and research in particular. We who work in educational technology support the university's mission to preserve, create, and disseminate knowledge.
A research hypothesis helps test theories. A hypothesis plays a pivotal role in the scientific method by providing a basis for testing existing theories. For example, a hypothesis might test the predictive power of a psychological theory on human behavior. It serves as a great platform for investigation activities.
A snapshot analysis of citation activity of hypothesis articles may reveal interest of the global scientific community towards their implications across various disciplines and countries. As a prime example, Strachan's hygiene hypothesis, published in 1989,10 is still attracting numerous citations on Scopus, the largest bibliographic database ...
Formulating Hypotheses for Different Study Designs. Generating a testable working hypothesis is the first step towards conducting original research. Such research may prove or disprove the proposed hypothesis. Case reports, case series, online surveys and other observational studies, clinical trials, and narrative reviews help to generate ...
Hypothesis refers to a supposition put forward in a provisional manner and in need of further epistemic and empirical support. Technology analysis explains the relationships underlying the source, evolution, and diffusion of technology for technological, economic and social change. Technology analysis considers technology as a complex system ...
7 Statistical hypothesis. A statistical hypothesis is when you test only a sample of a population and then apply statistical evidence to the results to draw a conclusion about the entire population. Instead of testing everything, you test only a portion and generalize the rest based on preexisting data. Examples:
Here are some research hypothesis examples: If you leave the lights on, then it takes longer for people to fall asleep. If you refrigerate apples, they last longer before going bad. If you keep the curtains closed, then you need less electricity to heat or cool the house (the electric bill is lower). If you leave a bucket of water uncovered ...
Before doing this, some background on hypothesis testing is worth providing. Some statistical knowledge about this procedure is assumed in this discussion. At the end of each section specific readings are recommended. Crisis in Science and Hypothesis Testing. Educational with Technology research is not done in isolation.
A hypothesis is a tentative statement about the relationship between two or more variables. It is a specific, testable prediction about what you expect to happen in a study. It is a preliminary answer to your question that helps guide the research process. Consider a study designed to examine the relationship between sleep deprivation and test ...
hypothesis. science. scientific hypothesis, an idea that proposes a tentative explanation about a phenomenon or a narrow set of phenomena observed in the natural world. The two primary features of a scientific hypothesis are falsifiability and testability, which are reflected in an "If…then" statement summarizing the idea and in the ...
Step 5: Present your findings. The results of hypothesis testing will be presented in the results and discussion sections of your research paper, dissertation or thesis.. In the results section you should give a brief summary of the data and a summary of the results of your statistical test (for example, the estimated difference between group means and associated p-value).
INTRODUCTION. Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses.1,2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results.3,4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the ...
A hypothesis is a statement or proposition that is made for the purpose of testing through empirical research. It represents an educated guess or prediction that can be tested through observation and experimentation. A hypothesis is often formulated using a logical construct of "if-then" statements, allowing researchers to set up experiments to determine its validity. It serves as the ...
A hypothesis is a tentative, testable answer to a scientific question. Once a scientist has a scientific question she is interested in, the scientist reads up to find out what is already known on the topic. Then she uses that information to form a tentative answer to her scientific question. Sometimes people refer to the tentative answer as "an ...
Research hypothesis. The primary research question should be driven by the hypothesis rather than the data. 1, 2 That is, the research question and hypothesis should be developed before the start of the study. This sounds intuitive; however, if we take, for example, a database of information, it is potentially possible to perform multiple ...